all
大家好,我是谢雪妮,很高兴参加这次面试;
在过去的六年里,我一直从事 Web 前端开发工作,主要使用 React 及其生态技术栈,也有扎实的前端工程化能力;
工作中参与了多个网站项目开发,主要包括 电商管理后台系统、BNPY 的分期付款网站,也涉猎过 web3 领域的 DApp 区块链应用,telegram 小程序等。
在这些项目中,我注重代码质量和团队协作,也乐于在项目中持续引入新技术和最佳实践。
很期待有机会加入贵公司,一起做更有挑战性的项目,谢谢!
1.html
h5 是什么?
H5 是一个产品名词,包含了最新的 HTML5、CSS3、ES6 等新的技术来制作的应用。
HTML5 是一个技术名词,指代的就仅仅是第五代 HTML。
defer vs async

html 第一行有什么用,Doctype?
告诉浏览器当前 HTML 是用什么版本编写的,DOCTYPE 会影响代码验证,并决定了浏览器最终如何显示你的 Web 文档。
<!DOCTYPE html> 表示是 html5,不需要引入 DTD
简述 requestAnimationFrame,优点
requestAnimationFrame Api 是在每一次重新渲染之前执行,这个 API 的出现,就是专门拿来做动画的。以前我们做动画,用的更多的是 setInterval 或者 setTimeout,但是这些 API 本意不是拿来做动画的。使用 requestAnimationFrame Api 拿到做动画,最大的优点就是频率是和浏览器重新渲染的频率一致。
用于在下一次浏览器重绘之前执行回调函数。它通常用于实现高性能的动画。优点是:
- 高效:它会在浏览器的刷新频率(通常是 60FPS)下调用回调函数,避免了不必要的重绘。
- 节能:当页面不可见或在后台时,requestAnimationFrame 会暂停调用,从而节省资源。(setTimeout 页面不可见时仍然执行)
- 平滑动画:它与浏览器的刷新同步,能提供更流畅的动画效果。
什么是 reflow?
reflow 的本质就是重新计算 layout 树。大概发生在浏览器渲染的第三个阶段,比较前置,
当进行了会影响布局树的操作后,比如元素的几何信息,宽高这些,就需要重新计算布局树。
什么是 repaint?
repaint 的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 repaint。
由于元素的布局信息也属于可见样式,所以 reflow 一定会引起 repaint。
移动端下适配不同屏幕的原理是什么,有几种方案?
- 流式布局、
- 媒体查询、
- rem + flexible、
- vw/vh、viewport 缩放等方案。
实际项目中我会根据场景选择,比如后台管理系统用媒体查询,H5 活动页用 rem 或 vw/vh,老项目可能用 viewport 缩放。针对字体、组件大小的适配,我更倾向 rem + postcss-pxtorem 或 vw,因为它们能结合设计稿精准还原。
- rem+动态的 font-size,这个方案分两步,一个是要根据客户端大小动态设置动态的 font-size
- 设置动态 font-size?
- 媒体查询(用的比较少) 弊端:需要写大量的媒体查询,其次是实时性不高,媒体查询只是个范围,断点
- js 动态修改:
- 手淘的方案 lib-flexible 也用的比较少,不更新了,由于 vw 已被广泛支持,该库的作者也推荐使用 vw 方案
- 调整 body font-size(根据 dpr)
- 计算 rem html 的 clientWidth / 10
- 监听 resize 和 pageShow 更新 2 步骤
- 自行实现
- 手淘的方案 lib-flexible 也用的比较少,不更新了,由于 vw 已被广泛支持,该库的作者也推荐使用 vw 方案
- rem 单位计算
- scss/less 换算
.px2rem(@px) { width: 1rem * (@px / 37.5) // 37.5 = 375 / 10, 375 是设计稿宽度 } - 库 postcss-pxtorem
- vscode 插件
- scss/less 换算
- 设置动态 font-size?
- 方案二 vw,这个是目前普遍在用的方案,vw 方案可以简单理解为 html font-size 设置为 10vw (开玩笑的方案)
- 直接使用 vw,vh,开发的时候开始用 px,用工具转换为 vw
- 手动换算
@vwUnit: 3.75 .px2vw(@px) { result: (@px / @vwUnit) * 1vw } - 库 postcss-px-to-viewport
- 手动换算
- 直接使用 vw,vh,开发的时候开始用 px,用工具转换为 vw
vw 相比于 rem 的优势:
- 不需要去计算 html 的 font-size 大小,也不需要给 html 设置这样 font-size;
- 不会因为设置 html 的 font-size 大小,而必须给 body 再设置一个 font-size,防止继承
- 因为不依赖 font-size 的尺寸,所以不用担心某些原因 html 的 font-size 尺寸被篡改,页面尺寸混乱
- vw 相比于 rem 更加语义化,1vw 是 1/100 的 viewport 的大小;
- 可以具备 rem 之前所有的优点;
- 废弃的
- 百分比 基本不用,因为不确定包含块,参照物很难统一
- flex 布局:辅助
2.css
CSS 几种解决方案的对比
- css module 是一种作用域隔离的 CSS 方案,它允许 CSS 代码在组件内部使用,而不会影响其他组件的样式
- css in js 主流的有
Styled Component,Emotion; 样式定义嵌入到 JavaScript,它允许在 JavaScript 代码中动态生成和管理样式。这个方案特别适用于组件化开发,它将样式与组件的逻辑、状态紧密结合,但他完全是运行时的 - tailwindcss 主打 utility classes 原子类的设计理念,目前应用广泛
- 预处理器( SASS、LESS 和 Stylus)为 CSS 提供了编程语言的特性,使得 CSS 的编写更具模块化和可维护性,可用变量/嵌套/mixin 等特性
- postcss CSS 后处理工具 构建过程中对 CSS 进行转换、优化、增强,支持各种功能,比如自动添加浏览器前缀、CSS 嵌套、自动优化代码等
- 运行时的方案有:styled-components、Emotion 的默认模式、TailwindCSS 的 JIT 模式。
- 非运行时:传统 CSS、SCSS、LESS、CSS Modules、Tailwind CSS 的非 JIT 模式、静态生成的 CSS-in-JS,Emotion 支持在构建阶段提取样式为静态 CSS 文件。
flex: 1 是什么意思?
全写为 flex: 1 1 0,这个元素要把父容器里剩下的空间尽可能“占满”,和其它也设置了 flex: 1 的元素平分空间。
- flex-grow: 1: 如果父容器中有多余空间,这个元素会按比例分配这些空间。多个元素设置 flex-grow: 1,它们会平分可用空间。
- flex-shrink: 1: 空间不足时,元素会按比例缩小。
- flex-basic: 初始的主轴尺寸为 0,也就是说元素初始不占空间,完全依赖 flex-grow 来扩展
简述 BFC,用以解决什么问题,如何触发
BFC 是块级格式化上下文,是浏览器的一种布局机制。它使元素形成一个独立的布局区域,内部元素不会影响外部布局。常用于清除浮动、避免 margin 合并、解决高度塌陷等问题。 可以理解 BFC 是一个封闭的大箱子,箱子内部的元素无论如何变化都不会影响外面的元素
如何触发 BFC:
float: left/right;元素浮动即触发 BFCposition: absolute/fixed绝对/固定定位会触发 BFCdisplay: inline-block;,display: table-cell;,display: flow-root;overflow: hidden/auto/scroll;常用于清除浮动,注意visible无效contain: layout;
特性及应用:
- 父子块级元素上下相邻时,margin 会塌陷,变成最大值。父元素设置 BFC(如 overflow: hidden)可阻止塌陷发生。
- BFC 可以包含浮动的元素(清除浮动), 子元素浮动后,父元素高度塌陷怎么办?设置父元素为 BFC;
- BFC 可以阻止元素被浮动元素覆盖
两个子元素 content 10px,padding 10px,margin 10px, 父元素总高度为多少
70px;
发生了三次 margin 塌陷:
- 第一次:第一个子元素的 margin-top,其实会变成父元素的 margin-top;
- 第二次: 第一个子元素的 margin-bottom 和 第二个子元素是 margin-top 会重叠为 10px;
- 第三次: 第二个子元素的 margin-bottom 实际也会变为 父元素的 margin-bottom 不计入高度
元素显隐的方案对比
- display none
- 完全从文档流中移除元素元素不占空间,可能触发回流,
- 不可点击,在事件响应上无法获取焦点,无法响应任何事件
- visibility hidden
- 只会触发重绘,是继承属性,
- 元素不可见,但仍然占据空间,
- 用户仍然可以与其交互,可以在冒泡阶段响应事件
- opacity 0
- 只是透明度为 0,
- 可以获得焦点,可以响应事件;
- ansolute zindex -9999,
- hidden 属性
介绍一下 css 样式优先级
CSS 样式优先级是由选择器的权重决定的,
- 内联样式优先级最高,1000
- 其次是 ID 选择器,100
- 再次是类选择器、属性选择器和伪类选择器,10
- 最后是元素选择器和伪元素选择器。1
权重通过累加计算,例如 #id .class div 的权重是 100 + 10 + 1 = 111。如果权重相同,后定义的样式会覆盖前面的样式。此外,!important 的样式优先级最高,但应谨慎使用以避免影响样式的维护性。
介绍下盒模型
box-sizing: content-box | border-box
- content-box(默认,标准盒模型)元素总体宽度(offersetWidth) = 设置的 width + padding + border,简单记忆(设置的 width 属性表示的是 content width, 总宽度还要加上其他的)
- border-box 元素总体宽度(offersetWidth)= 设置的 width,padding 和 border 会被向内挤压
介绍下 shadcn-ui
shadcn-ui 一个基于 tailwindcss 的组件库,但严格意义上不算是组件库,而是可重复使用的组件的集合,以 radix 为基础,利用了 radix 原子级组件逻辑,无样式的特性;轻量化,追求高度定制;
init 的时候
- 生成 shadcn.config.json, 存储主要配置
- 安装必要的依赖,比如 radix,lucide icon,CVA
- 更新 tailwind config,
add 的时候
- 检查输入的组件名称,无效就提示错误
- 下载组件模板
- 将组件代码复制到项目中
3.js
js 基础类型有哪些
number,string,bool,undefined,null,symbol(ES6), bigint(es10)
运算规则 TODO
算数运算
- 转化为数字再运算
- 特殊情况
- string + number = str 拼接
- NaN + 任何 = NaN
转换
[] + {} = [].valueOf() + {}.valueOf() = [] + {} = [].toString() + {}.toString() = '' + '[object object]' = '[object object]'
// {} 被 js 理解为块级作用域了
{} + [] = +[] = +'' = +0 = 0介绍下浅拷贝和深拷贝?深拷贝的方案?
基础类型,这类数据类型在内存中占据固定大小,保存在栈内存中,基本数据类型,直接复制值。 引用类型的数据存储在栈中的是对象的引用地址,而真实的数据存放在堆内存中。
浅拷贝: 只复制对象的第一层属性。引用数据类型(如对象或数组),只复制引用地址,拷贝后的对象与原对象共享同一块内存。
- 浅拷贝
Object.assign({}, obj) - 使用扩展运算符:浅拷贝
{ ...obj } [].concat(arr),arr.slice(0)
深拷贝: 复制对象的所有层级。拷贝后的对象与原对象完全独立,修改其中一个不会影响另一个。
JSON 方法(适用于简单对象): 深拷贝
JSON.parse(JSON.stringify(obj)缺点:
- 无法拷贝 函数/undefined/Symbol(会丢失)、
- 无法拷贝 NaN/Infinity/null(变为 null)、
- 无法拷贝 reg/Error/map/set/weakmap(变为空对象),
- 无法拷贝 date(变为字符串)。
- 会丢失对象的原型链
递归实现: 深拷贝 思路是
- null 或者非 obj 直接 return object
- 特殊类型的处理
- Array
obj.map(item => deepClone(item)) - Date
new Date(obj.getTime()) - RegExp
new RegExp(obj.source, obj.flags) - Set
new Set([...obj].map(item => deepClone(item))) - Map
- symbol
- Array
- 其他认为 obj,
Object.keys(obj).forEach(key => { clonedObj[key] = deepClone(obj[key]); })
弊端:循环引用无法解决 两个或者多个对象相互持有对方的引用,就形成了引用循环,导致的结果是内存泄漏。
报错:Maximum call stack size exceeded
解决方案:建立映射表,new weakmap()
- 终极方案:structuredClone,caniuse 上兼容性也达到 93% 了,还不错了 缺点是:无法拷贝 函数,undefined,symbol,DOM
介绍下原型和原型链
原型链是由多个对象的原型逐级连接形成的链式结构,当访问对象的属性或方法时,JavaScript 会沿着原型链逐层查找,直到找到目标属性或到达链的顶端(即 null); 每个对象都有个隐式原型(__proto__)或者 getPrototypeOf, 每个函数都有个原型(prototype 对象),用于存放一些属性和方法,实现继承
p.proto: Person.prototype
Person.prototype.proto: Object.prototype
Object.prototype.proto: null
Person.proto: Function.prototype
Object.proto:Function.prototype
Function.prototype.proto: Object.prototype
Function__proto__: Function.prototype
恶心的继承??????不想看!!!!
通过原型链实现继承的方式:
- 子类调用父类构造函数
Parent.call(this, name) - 继承原型
Child.prototype = Object.create(Parent.prototype) - 修复 constructor 指向
Child.prototype.constructor = Child
如何判断对象的原型链中是否包含某个原型
使用 instanceof 或 isPrototypeOf:
obj instanceof Constructor判断 obj 是否是 Constructor 的实例Constructor.prototype.isPrototypeOf(obj)判断 obj 的原型链中是否包含 Constructor.prototype
介绍下函数柯里化
接受多个参数的函数转换为接受单一参数的函数。 每次调用返回一个新函数,直到所有参数被提供为止。 优点是参数复用,可以固定部分参数,延迟计算
介绍下几种循环
按循环性能由高到低:
- for 可退出,知道循环次数的情况下最好使用他(性能最优)
- while/dowhile 可退出,适用于循环次数不确定,但需要满足某个条件时的场景
- forEach 不能退出,没有返回值;适用于循环次数未知,或者计算循环次数比较麻烦情况下使用效率更高,与之相对应是还有 map,区别是有返回值。
- for of 可退出,遍历可迭代对象(obj 不行),与 forEach() 不同的是,它可以正确响应 break、continue 和 return 语句,性能要好于 for in,但仍然比不上普通 for 循环,这个方法避开了 for in 循环的所有缺陷,for of 循环出的是 value。
- for in 可退出,遍历数组或者对象(循环出的是 key,是 string),通常用来遍历对象(包括原型链上的属性),建议不要用该方法来遍历数组,因为它的效率是最低的。在 ECMAScript 规范中定义了 「数字属性应该按照索引值⼤⼩升序排列,字符串属性根据创建时的顺序升序排列。
哪些地方不能使用箭头函数
一句话:用于消除函数的二义性 在 js 中(js 的设计缺陷,function 和 class 不分),函数有两种用法,第一种就是我们常见的指定序列,定义一个函数再执行,第二种用法就是将他当作构造器,用 new 来创建,这个也能用来创建对象的实例,这就是函数的二义性。
ES6 提出 Class 语法和箭头函数,Class 这个就是直接告诉我们,这不是一个简单的函数,无法使用指定序列来调用,会报错,必须 new ,箭头函数就是个简单的执行序列,和面向对象无关,所以他的局限性,或者说什么场景下无法使用箭头函数,其实就是和面向对象有关的场景下 this,new 等就不适用箭头函数了,也没有 arguments
Js 事件模型
早期的浏览器是没有事件流的,ie 和网景在事件处理上存在分歧,
- ie 认为事件是从目标节点向根节点冒泡传播的,目标节点最早触发,根节点最后触发;
- 网景提出了事件捕获模型,认为事件先从根节点触发,
这种差异导致了跨浏览器兼容问题,为了解决这个问题,W3C 提出了标准化事件模型,默认情况下,事件以冒泡的方式触发,可通过 addEventListener 第三个参数修改为 true 改为 捕获。
分为三个阶段:
- 捕获阶段(根节点向目标元素传播,经过每一个父节点)addEventListener true
- 目标阶段(到达目标阶段)
- 冒泡阶段(目标元素向上冒泡回到根节点)默认都冒泡
聊一下 js 事件循环,两句话
单线程是异步产生的原因
事件循环是异步的实现方式
如何理解 JS 的异步
JS 是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。承担着诸多的工作,比如渲染页面,执行 js 都在其中。
如果用同步的方式,极有可能导致主线程产生阻塞,从而导致消息队列中很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白白消耗事件,另一方面导致页面无法及时更新,给用户造成卡死的假象。
所以浏览器采用异步的方式来解决。具体做法是当某些任务发生时,比如计时器,网络等,主线程会将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的末尾排队,等待主线程调度执行; 在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
事件循环是什么
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式; 在 Chrome 的源码中,他开启了一个不会结束的 for 循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列末尾即可; 过去把消息队列简单分为宏任务和微任务,这种说法已无法满足目前浏览器的复杂程度; 根据 W3C 官方的解释: 每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于不同队列。队列有优先级之分,在每一次循环中,由浏览器自行决定取哪个队列的任务; 但浏览器必须有一个微队列,微队列的任务最高优先级,必须优先调度执行;
任务没有优先级,在消息队列中先进先出; 消息队列有优先级
计时器能做到精确计时吗,为什么
- 不是原子钟,无法做到精确计时;
- 按照 W3C 标准,浏览器实现计时器,如果嵌套层级超过 5 层,则会带有 4ms 的最少时间,这样在计时时间少于 4ms 时又带来了偏差
- 受事件循环影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差
- 有什么解决方案?
- 在 setTimeout 中加入时间校正
- requestAnimationFrame
- web worker
- performance.now 替代 Date
- performance.now 返回一个以 毫秒为单位的时间戳,但精度可以达到微秒; Date 只到 毫秒
- performance.now 是从浏览器/程序启动到当前的时间,与系统时钟无关,不会因用户手动修改时间或系统同步时间而改变;Date.now() 则是基于系统当前时间,可能因系统时间调整而发生跳变或回退
介绍下 requestIdleCallback
requestIdleCallback 是浏览器提供的一个 API,用于在浏览器空闲时执行低优先级任务。它允许开发者在不影响用户体验的情况下执行后台任务,例如数据预加载、日志记录等
- 为什么 react 没有用 requestIdleCallback?要自定义 scheduler
- 兼容性问题,一个是不是所有浏览器都支持,另一个是 React 是一个跨平台,跨浏览器的解决方案,不能依赖于特定 API
- 无法保证优先级
- 无法保证任务的执行时间
- 自定义调度器(基于 MessageChannel)提供了更高的灵活性和性能优化。
打印 timeRemaining() 的时候会发现,部分时间超过了 16.66ms,可能是 50ms 等,这是为什么呢? 虽然每一帧绘制的时间约为 16.66ms,但是如果屏幕没有刷新,那么浏览器会安排长度为 50ms 左右的空闲时间。
为什么是 50ms?
根据研究报告表明,用户操作之后,100ms 以内的响应给用户的感觉都是瞬间发生,也就是说不会感受到延迟感,因此将空闲时间设置为 50,浏览器依然还剩下 50ms 可以处理用户的操作响应,不会让用户感到延迟。
介绍下 webwoker,限制有哪些,应用场景
是一种在浏览器中运行的独立线程,用于执行耗时的任务而不阻塞主线程(UI 渲染线程);主线程和 Worker 通过 postMessage 和 onmessage 进行双向通信。
Web Worker 的限制有哪些?
- 无法操作 DOM
- 受限的 API
- 同源限制
- 通信开销
Web Worker 的实际使用场景
- 复杂计算:如大数据处理、图像处理、加密解密等。
- 文件处理:如文件解析(CSV、JSON)、压缩和解压缩。
- 实时数据处理:如音视频流处理、实时图表渲染。
- Web 应用性能优化:如在 React/Vue 应用中,将复杂逻辑放入 Worker 中执行。
介绍一下闭包,使用场景
内存泄漏:有垃圾没有被回收;
垃圾:不用的东西就叫垃圾;
闭包:函数 + 词法环境;一个函数可以访问其定义时作用域中变量的机制,即使这个函数在外部被调用时,依然能访问那个作用域
用于封装私有变量、实现柯里化、事件绑定状态管理等场景
闭包与内存泄漏的关系
闭包中的参数不会被回收吗?
很简单的问题,如果闭包还在用,那么他所携带的参数也就不算是垃圾,不应该被回收,如果闭包不再被引用,且参数不被别的地方使用,那么这些参数就会被回收
闭包与内存泄漏的关系就是:
- 有一些本该被回收的函数没有被回收,从而导致其关联的词法环境也无法被回收,最终造成内存泄漏;
- 当多个函数共享一个词法环境的时候,可能会造成词法环境的膨胀,从而出现无法访问且无法回收的内存空间
typeof vs instanceOf
typeof null = "object"是一个已知的 JavaScript 设计缺陷。- typeof 对于数组、对象、null 都返回 “object”,无法区分具体的对象类型。
- instanceof 用于检测某个对象是否是某个构造函数的实例,返回一个布尔值
一般使用 typeof 检测基本数据类型。使用 instanceof 检测对象的具体类型。对于特殊情况(如 null 和数组),需要额外处理。
function checkType(value) {
if (value === null) return "null";
if (Array.isArray(value)) return "array";
return typeof value;
}介绍一下 webStorage
cookie 存储容量最小,只有 4kb,必须是字符串,可设置过期时间,会跟随请求一起发送
storage 的存储容量一般在 5MB 左右,也必须是字符串,其中 localStorage 是永久的,sessionStorage 是会话级的,会随浏览器关闭而自动销毁
indexDB 存储容量较大,一般取决于硬盘,大数据量的存储,就不建议放在 storage 里,可用考虑 indexDB 或者服务端存储
Cookie - 如何保证安全
- domain 和 path
- 如果未设置 domain 属性,Cookie 的作用域默认为当前域名(不包括子域名)
- 如果设置了 domain 属性,Cookie 可以被指定域名及其子域名访问。
- 设置了 path 确保只有特定路径下的页面能够访问 Cookie
- samesite 跨站:域名不一致,同源策略作为浏览器的安全基石,其「同源」判断是比较严格的,相对而言,Cookie 中的「同站」判断就比较宽松:只要两个 URL 的有效顶级域名 + 1 相同即可,不需要考虑协议和端口。例如 taobao.com 等。 跨站要不要把 cookie 带过去,就取决于 SameSite;
- None 必须配合 secure,否则无效
- Lax 默认值,只有 GET 请求和导航请求会带上 Cookie,其他类型的跨站请求不会带上 Cookie,对超链接放行,比如 a 的 href
- strict:阻止所有 cookie 发送
- http-only:属性可以使 Cookie 只能通过 HTTP 请求访问,不能通过 JavaScript 访问。这可以防止跨站脚本攻击(XSS)通过 JavaScript 读取 Cookie
- secure:只有在通过 HTTPS 协议的安全连接中,Cookie 才会被发送
token 存放在哪里
便捷性考虑,存放在 localStorage 是没问题的,安全不是 token 负责的,token 的职责只是做请求会话认证的,Token 是防止篡改的 不是防泄露的
单点登录,超纲了
是一种身份验证和授权机制,使用户能够在一个会话中使用多个应用或系统而不必多次登录。它简化了用户的登录体验,
Math.max 入参为数组要怎么实现
- Math.max.apply(null, arr);
- Math.max.apply(…arr);
介绍下 Object.defineProperty
用于精确地添加或修改对象的属性,不仅能设置值,还可以定义这个属性的行为(是否可枚举、是否可写、是否可配置等)。 是 Vue 2 响应式系统的核心,也常用于底层封装、兼容处理、属性控制等场景。
const obj = {};
Object.defineProperty(obj, 'name', {
value: 'Alice',
writable: false
});
obj.name = 'Bob';
console.log(obj.name); // "Alice"const user = {};
Object.defineProperty(user, 'password', {
value: '123456',
enumerable: false
});
console.log(Object.keys(user)); // []
console.log(user.password); const obj = {
_age: 18
};
Object.defineProperty(obj, 'age', {
get() {
console.log('get age');
return this._age;
},
set(val) {
console.log('set age', val);
this._age = val;
}
});
obj.age = 20; // set age 20
console.log(obj.age); // get age → 20- Object.defineProperty 和 Object.assign 区别?
- assign 是浅拷贝,只复制值,不控制属性行为。
- defineProperty 可以控制属性行为,更底层。
- defineProperty 实现响应式的原理?
- 拦截对象属性的 get 和 set,在访问时收集依赖,在设置时触发更新。
如何判断对象为空
判断对象为空可以使用 Object.keys(obj).length === 0,这是最主流的写法。如果要更严谨地判断包括 Symbol 类型的属性,我们可以使用 Reflect.ownKeys(obj).length === 0。此外在做判断前建议进行类型和 null 检查。
更简单一点的还有 JSON.stringify(obj) === '{}', Object.getOwnPropertyNames(obj).length === 0;
use strict 模式
普通函数调用,this 在严格模式下是 undefined,非严格是 window;
4.ts
ts vs js
一句话总结:JavaScript 是弱类型的动态语言,而 TypeScript 是强类型的静态语言,它增强了 JS 的可维护性和开发体验。
- TypeScript:
- 是一种静态类型语言,支持类型检查。
- 在编译阶段捕获类型错误,减少运行时错误。
- 支持自定义类型、接口、枚举等。
- 适用于大型项目,团队协作,需要高可维护性和类型安全的项目
- JavaScript:
- 是一种动态类型语言,变量的类型在运行时确定。
- 没有类型检查,容易引发运行时错误。
- 适用小型项目,快速开发,不需要严格类型检查的场景
如何定义 function 的 arguments
arguments 可以用 IArguments 来定义; 其实 IArguments 就是 ts 实现定义好的 interface
interface IArguments {
[index: number]: any;
length: number;
callee: Function;
}any vs unknown vs never vs void
ts 中按以下顺序来定义强度
- top type:any,unknown
- any 赋值给别人或者被赋值,都可以
- unknown 赋值给别人不行(自身和 any 是行的),被赋值可以,且无法读取任何属性
- Object 万物即对象
- Number String Boolean
- number string boolean
- 1 ‘str’ false
- bottom type: never, 无法到达的类型,type a = string | never,never 会被忽略掉

Object vs object vs {}
Object:万物即对象;
const obj1:Object = 'string' // This is invalid
const obj2:Object = 123 // This is valid
const obj3:Object = true // This is valid
const obj4:Object = [] // This is valid
const obj5:Object = {} // This is valid
const obj8:Object = function(){} // This is valid
// 报错
const obj6:Object = null // This is invalid
const obj7:Object = undefined // This is invalidobject:引用类型(除了原始类型),常用于泛型约束;
const obj3:object = { name: 'test' }; // This is valid
const obj4:object = []; // This is valid
const obj5:object = function(){} // This is valid
// 报错
const obj1:object = 'strng'; // This is invalid
const obj2:object = 123; // This is invalid{} 可以理解为 new Object
const obj1:{} = 'string'; // This is valid;
const obj2:{} = 123; // This is valid;
const obj3:{} = true; // This is valid;
const obj4:{} = []; // This is valid;
const obj5:{} = {name:'xxn'}; // This is valid;
// 报错
obj5.age = 10 // This is invalid;interface vs type
interface
- 定义对象的结构,仅限对象结构
- 支持继承 (extend)
- 重复定义支持合并
- 性能更优
- interface 不可以赋值给 record;如果想要将一个 interface 赋值给另一个 record ,需要给 interface 添加索引签名;
type
- 定义类型别名,更灵活
- 支持交叉类型 (&)
- 不允许重复定义
- 性能略低
- 可以直接赋值给 record
原因是因为 需要明确 interface 的属性后才可以赋值给 record,interface 是可以生命合并的,这一点导致了 interface 是属性不明确
interface Obj {
name: string;
}
interface IndexObj {
name: string;
[key: string]: string;
}
type Obj2 = {
name: string
}
const interfaceObj: Obj = { name: 'test' }
const interfaceIndexObj: interfaceIndexObj = { name: 'test' }
const typeObj: Obj2 = { name: 'test' }
const obj:Record<string, string> = interfaceObj; // This is invalid;
const obj2:Record<string, string> = typeObj; // This is valid;
const obj3:Record<string, string> = interfaceIndexObj; // This is valid;介绍下泛型
让类型也可以像参数一样传递,也可以叫做动态类型,
- react 中
const [num, setNum] = useState<number>(0)就是泛型的一种运用 type A<T> = string | number | T;- 泛型约束 extend 关键字对泛型参数进行约束
interface Lengthwise { length: number; } function logLength<T extends Lengthwise>(item: T): void { console.log(item.length); } logLength("Hello"); // 输出:5 logLength([1, 2, 3]); // 输出:3 // logLength(42); // 报错:number 没有 length 属性
泛型 vs 联合类型: 泛型是动态的,可以在使用时具体指定,联合类型是静态的,表示固定的类型集合
泛型的局限性
- 运行时会擦除,无法在运行时获取类型信息
- 不能用于定义静态成员
- 不能直接用于创建实例??
枚举 (enum) vs 常量枚举 (const enum)
枚举:在编译后的 JavaScript 中会生成一个对象,用于存储枚举的映射关系。
常量枚举:在编译后的 JavaScript 中会被直接内联,不会生成额外的对象。
枚举:
- 编译结果是对象
- 性能略低,运行时有额外开销
- 如果需要运行时访问枚举值,推荐使用
- 支持动态访问
常量枚举:
- 编译后直接内联
- 性能较高,无运行时开销
- 如果只需要编译时使用枚举值,推荐使用
- 不支持动态访问
类型守卫是什么
一种在运行时检查变量类型的技术,typeof, instanceOf, 自定义 is, in
const vs readonly
const
- 用于定义常量
- 变量不能重新赋值
readonly
- 用于类属性或接口字段
- 属性不能被修改
- 仅在 ts 中检查
ts 中 declare 是什么
简单理解为:这个东西不是我写的,但是我知道
只负责告知编译器,声明一个东西,编译后不产生实际代码
ts 映射文件是什么
当你编译 .ts 文件时,TypeScript 可以生成一个 .js.map 文件。是一个用于调试的工具,它在编译后将 JavaScript 代码与原始 TypeScript 源码对应起来,使开发者能够在浏览器中调试 TypeScript,而不是编译后的 JavaScript。
在 tsconfg 中的 compilerOptions 的 sourceMap 来打开
ts 装饰器是什么
是一种特殊的语法,用于对类、方法、属性、参数等进行注解和扩展。它本质上是一个函数,能够在编译时(而非运行时)修改或增强目标对象的行为。
ts implement 是什么
你如何用 TypeScript 限制某个类必须实现某种结构?
答:使用 interface + implements
元组 vs 数组
元组越界之后将会以联合类型推断
5.eS6
super 原理
父类的 prototype.constructor.call
ES module vs common.js
CJS: this exports module.exports 是一个东西
- CMJ 是社区标准,ESM 是官方标准
- CMJ 是使用 API 实现的模块化,ESM 是使用新语法实现的模块化
- CMJ 仅在 node 环境中支持,ESM 各种环境均支持
- CMJ 是动态的依赖,同步执行。ESM 既支持动态,也支持静态,动态依赖是异步执行的。
- CMJ 不支持 Tree Shaking。ESM 支持 Tree Shaking
- ESM 导入时有符号绑定???,CMJ 只是普通函数调用和赋值:
- CMJ 导入的值是拷贝,ESM 导入的值是实时绑定
ES6 模块化如何改善代码结构和可维护性?
- 明确导入导出
- 避免全局命名污染:通过局部作用域限制了变量的可见性
- 提高代码复用性
- 促进团队协作
- 优化加载性能
ES6 模块化如何解析的
https://juejin.cn/post/7166046272300777508#heading-15
let vs const vs var
var 的鸡肋:
- 反直觉的函数作用域
- 反直觉的变量提升
- 自作主张的挂载
var a = 1 // 等同于 window.a = 1
var、let、const 三者区别可以围绕下面五点展开: 三者都有变量提升,只是 let 和 const 提升后,也就是先被创建出来但并未赋值 undefined,有暂时性死区; 暂时性死区就是提升的那一行到声明变量的那一行中间的区域,称为暂时性死区,不能访问变量
- 污染全局:var(会被挂载到全局),window.a, 但是 let 不会,但是二者都可以跨越 script 标签
- 变量提升: var let const
- 暂时性死区 temporal die zone:let const
- 块级作用域{}:let const
- 重复声明:var
- 修改声明的变量:var let
promise 和 async/await 的优缺点
Promise 更适合链式调用,可读性较差但灵活;
async/await 更像同步代码的写法,可读性强,语义清晰。
async/await 的原理
async function 一定返回一个 Promise
await 是等待这个 Promise 的结果,暂停当前函数的执行(非阻塞)
遇到 await,函数挂起,JS 引擎把后续代码包装成回调函数,注册到 Promise 的 .then();
当前任务结束,事件循环会在未来某个时间点继续执行这个回调;
错误会被抛出,可以通过 try/catch 捕获。
本质上就是 “暂停 + 回调注册 + 恢复执行”
介绍下垃圾回收
不再需要但还占用内存的叫做垃圾。
主流策略是:标记清除(用的比较多)
- 标记空间中的可达值:根开始遍历,可遍历到的是可达的
- 回收「不可达」的值所占据的内存
- 做内存整理
v8 会使用分代垃圾回收机制来优化垃圾回收: 具体来说:浏览器将数据分为两种,一种是「临时」对象,一种是「长久」对象
长久对象有:生命周期很长的对象,比如全局的 window、DOM、Web API 等等,这类对象称为老生代,慢慢回收,用主回收器
临时对象有:函数内部声明的变量,或者块级作用域中的变量。当函数或者代码块执行结束时,作用域中定义的变量就会被销毁。这类对象称为新生代对象,很快就变得不可访问,会用副回收器
浏览器中不同类型变量的内存释放时机
- 栈内存中的变量:基本类型变量:作用域结束自动释放
- 堆内存中的变量
- 局部对象:失去引用时由垃圾回收器释放
- 全局对象:页面关闭或手动解除引用时释放
- 特性情况
- 闭包变量:闭包对象失去引用时释放
- 相关变量:元素移除且解除引用时释放
哪些情况会导致内存泄露?如何避免?
意外的全局变量
- 使用严格模式
'use strict' - 始终使用
let/const声明变量 - ESLint 配置
no-undef规则
- 使用严格模式
被遗忘的定时器和事件监听器,记得清除
DOM 引用
map/set 和 weakmap/WeakSet
waekxxx 没有 遍历/size/clear 方法,是因为 key 是弱引用,随时可能消失,遍历机制无法保证成员的存在,很可能刚刚遍历结束,成员就取不到了。
const cache = new Map();
cache.set(someObject, data);const cache = new WeakMap();
cache.set(someObject, data);
// 当 someObject 不再被引用时,数据会被自动回收WeakMap 只接受对象(null 除外)和 Symbol 值作为键名
WeakMap 的键名所指向的对象,不计入垃圾回收机制。
键名所引用的对象都是弱引用,即垃圾回收机制不将该引用考虑在内。因此,只要所引用的对象的其他引用都被清除,垃圾回收机制就会释放该对象所占用的内存。也就是说,一旦不再需要,WeakMap 里面的键名对象和所对应的键值对会自动消失,不用手动删除引用。 大佬链接
介绍下迭代器
是一个具有 next() 方法的对象,每次调用返回一个 { value, done } 对象。
setTimeout(fn, 0) 多久执行?
根据 HTML 5 标准,setTimeout 推迟执行的时间,最少是 4 毫秒。如果小于这个值,会被自动增加到 4。这是为了防止多个 setTimeout(f, 0) 语句连续执行,造成性能问题。
介绍一下 Promise 以及用法
Promise 用于避免回调地狱(Callback Hell),提高异步操作的可读性和可维护性
Promise(A).catch(f1).then(f2) ,f1 执行后 f2 会执行吗,为什么
- 如果 f1 处理了错误并返回一个值,f2 会接收到该值。
- 如果 f1 抛出错误或返回一个被拒绝的 Promise,f2 不会执行,错误会继续向下传递。
假设我的 promise 里面全部都是同步代码,promise 里面没有做任何异步,不写 pending 是不是也可以?
不行,一个是违反 Promise/A+ 规范,且状态不可逆的特性里,需要对 状态进行 pending 的判断
在 setTimeout 里产生一个 promise,当前的 promise 会在当前次执行掉吗?还是在下一次循环里执行?
settimeout 的整个回调函数先进入宏任务队列,一步一步走
Promise 值穿透是什么
指在 .then() 链中,如果某个 then 没有传入处理函数,Promise 会自动将上一个 resolve 的值原样传递给下一个 then;Promise.resolve(1).then(2).then(Promise.resolve(3)).then(console.log)
逐步解析(重点在于 .then(…) 中的非函数传入行为,根据 A+ 规范,resolve 里返回非函数,会覆盖为 value=> value, 2 和 Promise.resolve(3) 都不是函数
Promise 的常用方法
- Promise.resolve: 创建一个状态为“已完成(fulfilled)”的 Promise
- Promise.reject: 创建一个状态为“已拒绝(rejected)”的 Promise
- Promise.all: 按序返回成功结果,如果一个失败就立刻失败
- Promise.allSettled: 按序返回成功/失败结果
[{statue: 'fulfilled',value:'xxx'},{statue:'rejected',reason:'xxx'}] - Promise.any: 返回第一个成功,所有都失败,则失败
- Promise.race: 比赛,谁先执行完就返回谁,无论成功失败
- Promise.withResolvers(2024 new):暴露其 resolve/reject 方法的写法
const { promise, resolve, reject } = Promise.withResolvers(); setTimeout(() => { resolve("OK"); }, 1000); promise.then(console.log); // 1 秒后输出:OK - Promise.try (2025 new):Promise.try 可接收同步或异步函数,然后做统一的错误处理。这等同于 new Promise(resolve => resolve(f())),相比 Promise.resolve().then(f) 会少浪费一个 tick。
Promise.all 是串行还是并行
Promise.all 会**并发**执行所有传入的 Promise,等待全部完成后再进入 .then(),但按序返回结果 ECMAScript stage 有哪几个阶段
- Stage 0 : Strawman(草案,任何人都可以提出想法,非正式提案
- Stage 1: Proposal(提案), 开始讨论问题、动机、初步 API 设计
- Stage 2: Draft(草案), 草案文本写入规范,API 设计明确
- Stage 3: Candidate(候选), 已完成设计,征求实现者(浏览器/Node)反馈 |
- Stage 4: Finished(完成) , 被采纳为正式标准,进入 ECMAScript 规范
介绍下 Proxy
用于创建一个代理对象,可以拦截和自定义对另一个对象的各种操作,如:读取属性、设置属性、函数调用等。
- vue2 用
Object.defineProperty(), vue3 用 Proxy; Object.defineProperty()只能监听已有属性 ,Proxy 可动态监听新增/删除)Object.defineProperty()在数组响应式支持需要需要重写数组方法,Proxy 原生支持Object.defineProperty()兼容性更好,支持 IE,proxy 不行,是新语法
介绍下 Reflect
理解成是“更底层、更标准”的 Object 方法集合
Reflect.get(obj, key)比obj[key]更一致- 搭配
Proxy更方便,handler 中常用Reflect保持行为一致 - 返回值更统一(true/false), 比如
Reflect.set()不抛错,而是返回布尔值 - 替代一些
Object方法,如Reflect.ownKeys()替代Object.keys()+Object.getOwnPropertySymbols()
介绍下 Symbol
初衷是为了解决对象属性 key 重复的问题, 接收 string | number | undefined;
const a = Symbol()
const a1 = Symbol('key')
const a2 = Symbol(1)
const a3 = Symbol(false) // 报错如何让两个 Symbol 全等?
`Symbol.for('xxn') === Symbol.for('xxn')` for 方法会去找是否已注册过当前 key,如果有就直接拿来用,不会再创建如何遍历带有 symbol 的对象?
- for in 不行
- Object.keys 不行
- Object.getOwnProperty 不行
- Object.getOwnPropertySymbols 可以,但是其他属性读不到
- Relect.OwnKeys 可以的
6.design
在面向对象软件设计过程中针对特定问题的简洁而优雅的解决方案。通俗一点说,设计模式就是给面向对象软件开发中的一些好的设计取个名字。
介绍下工厂模式
直接调用即可返回新对象的函数
- axios.create 基于传入的配置,创建一个新的请求对象,可以用来设置 base url
介绍下单例模式
单例对象整个系统需要保证只有一个存在
class SingleTon {
constructor() {}
// 私有属性,保存唯一实例
static #instance;
// 获取单例的方法
static getInstance() {
if (SingleTon.#instance === undefined) {
// 内部可以调用构造函数
SingleTon.#instance = new SingleTon();
}
return SingleTon.#instance;
}
}- 组件库中的 toast,notify 之类的组件,保证单例
介绍下观察者模式
在对象之间定义一个一对多的依赖,当一个对象状态改变时,所有以来的对象会自动收到通知
- dom 事件绑定
window.addEventListener('load', () => {
console.log('load 触发 1')
})
window.addEventListener('load', () => {
console.log('load 触发 2')
})
window.addEventListener('load', () => {
console.log('load 触发 3')
})- vue 中的 watch
介绍下发布订阅模式
类似观察者模式,区别是一个有中间商(发布订阅模式),一个没有中间商(观察者模式)
- vue2 中的 EventBus
介绍下原型模式
在原型模式下,当我们想要创建一个对象时,会先找到一个对象作为原型,然后通过克隆原型的方式来创建出一个与原型一样(共享一套数据/方法)的对象。在 JavaScript 中,Object.create 就是实现原型模式的内置 api
原型模式:
- 基于某个对象,创建一个新的对象
- JS 中,通过 Object.create 就是实现了这个模式的内置 api
- 比如 vue2 中重写数组方法就是这么做的
创建的方式是通过 Object.create 进行浅拷贝
重写的时候:
- 调用数组的原方法,获取结果并返回—方法的功能和之前一致
- 通知了所有的观察者去更新视图
const app = new Vue({
el: "#app",
data: {
arr: [1, 2, 3],
},
});
app.arr.push === Array.prototype.push; //false介绍下代理模式
拦截与控制 与目标对象的交互
- 比如可以通过缓存代理:
- 缓存获取到的数据
- 拦截获取数据的请求:
- 已有缓存:直接返回缓存数据
- 没有缓存:去服务器获取数据并缓存
- 提升数据获取效率,降低服务器性能消耗
介绍下迭代器模式
提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。简而言之就是:遍历
自定义可迭代对象:
需要符合 2 个协议:
- 可迭代协议:
- 给对象增加属方法 Symbol.iterator{}
- 返回一个符合迭代器协议的对象
- 迭代器协议
- 有 next 方法的一个对象,内部根据不同情况返回对应结果:
- {done:true}, 迭代结束
- {done:false,value:‘xx’}, 获取解析并接续迭代
- 有 next 方法的一个对象,内部根据不同情况返回对应结果:
const obj = {
[Symbol.iterator]() {
const arr = [1, 2, 3, 4, 5];
let index = 0;
return {
next() {
if (index < arr.length) {
return { value: arr[index++], done: false };
} else {
return { done: true };
}
},
};
// --- generator function ---
// function* generator() {
// yield 1
// yield 2
// yield 3
// }
// const res = generator()
// return res
},
};
for (const element of obj) {
console.log(element);
}7.engine
模块化解决了什么问题,有哪些标准
主要为了文件级的问题
- 全局污染
- 依赖混乱
为了解决这些问题,提出了一些标准
- Commonjs CJS
- AMD
- CMD
- UMD
- ESM
前面四个是民间标准,社区出的;ESM 是官方的
AST 分为几个阶段
抽象语法树
- 词法分析 input = tokenizer => token
- 语法分析 token = parser => ast
- 代码转换 ast = traverse => new ast
- 合成产物 new ast = generate => output
AST 规范
ESTree: 初衷通过社区的力量,保证和 es 规范的一致性,通过自定义的语法结构来表述 JavaScript 的 AST,后来随着知名度越来越高,多位知名工程师的参与,使得变成了事实意义上的规范,目前这个库是 Mozilla 和社区一起维护的。ESTree spec 和 Parser API 都是定义一种语法表达的标准,这种标准生成的结构就是 AST。大部分流行的 JS 源码操作工具都是基于 AST 实现的
常见 AST 节点类型
- 声明类型:
VariableDeclaration,FunctionDeclaration,ClassDeclaration - 表达式类型:
Identifier,Literal,BinaryExpression,CallExpression - 语句类型:
BlockStatement,IfStatement,ForStatement,ReturnStatement
babel - 编译流程
- 解析(Parsing):将代码解析为抽象语法树(AST),使用 @babel/parser 把源码转为 AST
- 转换(Transformation):通过插件对 AST 进行处理和修改,使用 @babel/traverse 修改 AST 节点
- 生成(Code Generation):将 AST 转换为新的代码字符串,使用 @babel/generator
Babel 常见的 preset 有哪些?
- @babel/preset-env:按目标环境转换 ES6+ 代码(最常用)
- @babel/preset-react:转换 JSX
- @babel/preset-typescript:转换 TypeScript
- @babel/preset-flow:Flow 类型支持
babel vs polyfill
- babel 是转译功能(语法转换),比如 ES6+ 转化为 ES5,是编译时处理的,比如
@babel/preset-env - Polyfill 是做 api 补丁的,提供缺失的 API,是运行时依赖于环境是否支持的,一般使用
core-js
webpack 理念
webpack 中的这种万物皆模块的理念实际上的蛮值得我们思考的,因为他确实打破了我们传统中在页面去引入各种各样资源的这种固化思维,让我们可以在业务代码中去载入一切所需资源,这样真正意义上让 js 去驱动一切;
webpack 配置文件常用的属性有哪些
- 基础配置:entry、output
- 模块配置:module.rules
- 插件配置:plugins
- 开发服务器:devServer
- 优化配置:optimization
- 解析配置:resolve
- 性能配置:performance
- 模式配置:mode
- 目标配置:target
- 其他配置:externals、stats
webpack 构建流程
一个串行的过程:
- 初始化:启动构建,从 webpack.config 和 shell 读取配置参数并合并
- 根据参数实例化一个 compiler,并实例化插件,在 webpack 的事件流上去挂一些钩子,使得插件在整个构建过程中具备改动和产出结果的能力,run 开始编译
- 确定入口,读取 entry 入口,并进行依赖收集
- 依赖 loader 进行编译,递归的找到所有依赖文件
- 完成模块编译,得到每个模块被翻译后的内容以及他们之间的依赖关系,输出依赖关系图
- 生成资源,根据入口和依赖关系图,组装成一个一个 chunk,再把 chunk 合并成一个单独的文件并加入输出列表,这一步是可以修改输出文件的最后机会,比如 code split
- 输出文件到 output
webpack 官方的钩子有多种不同的执行顺序的,讲一下这个执行顺序是怎么样去定义的
Webpack 的钩子机制基于 Tapable 库,提供了多种类型的钩子(如同步钩子、异步钩子等),并且这些钩子在 Webpack 的构建流程中按照特定的顺序执行。
- 生命周期顺序:钩子按照 Webpack 的构建流程依次执行,从初始化到输出。
- 插件注册顺序:先注册的插件的钩子会先执行。
- 优先级控制:通过 enforce 属性(pre、默认、post)调整钩子的执行顺序。
- 异步钩子类型:串行钩子按顺序执行,并行钩子同时执行。
webpack 中 complier 和 compliation 都是什么意思吗
- compiler 对象记录着构建过程中 webpack 环境与配置信息,整个 webpack 从开始到结束的生命周期。针对的是 webpack。
- compilation 对象记录编译模块的信息,只要项目文件有改动,compilation 就会被重新创建。针对的是随时可变的项目文件。
介绍下 webpack - loader,为什么是 自下而上,自右向左的?
其本质为函数,函数中的 this 作为上下文会被 webpack 填充,因此我们不能将 loader 设为一个箭头函数
函数接受一个参数,为 webpack 传递给 loader 的文件源内容
函数中 this 是由 webpack 提供的对象,能够获取当前 loader 所需要的各种信息
函数中有异步操作或同步操作,异步操作通过 this.callback 返回,返回值要求为 string 或者 Buffer
为什么是 自下而上,自右向左的? 这是因为每个 loader 是一个函数,遵循管道式设计,后一个 loader 的输出是前一个 loader 的输入。Webpack 会先从 use 数组的最后一个 loader 开始处理最原始的资源,然后将结果逐层传递给前面的 loader,最终返回给 Webpack 打包流程。所以 loader 执行顺序严格遵循从右向左、从下到上的原则。
webpack - plugin
由于 webpack 基于发布订阅模式,在运行的生命周期中会广播出许多事件,插件通过监听这些事件,就可以在特定的阶段执行自己的插件任务
如果自己要实现 plugin,也需要遵循一定的规范:
- 插件必须是一个函数或者是一个包含 apply 方法的对象,这样才能访问 compiler 实例
- 传给每个插件的 compiler 和 compilation 对象都是同一个引用,因此不建议修改
- 异步的事件需要在插件处理完任务时调用回调函数通知 Webpack 进入下一个流程,不然会卡住
webpack complier 和 compilation
webpack 编译会创建两个核心对象:
- compiler:包含了 webpack 环境的所有的配置信息,包括 options,loader 和 plugin,和 webpack 整个生命周期相关的钩子
- compilation:作为 plugin 内置事件回调函数的参数,包含了当前的模块资源、编译生成资源、变化的文件以及被跟踪依赖的状态信息。当检测到一个文件变化,一次新的 Compilation 将被创建
webpack 常用的 plugin 有哪些
- HtmlWebpackPlugin 自动生成 html 文件,并将打包后的 js 插入,可指定 template
- MiniCssExtraPlugin 将 css 提取为单独的文件
- HotModuleReplacementPlugin 提升开发效率
webpack 热更新的原理
Webpack HMR 的核心是:在运行时检测代码变更,把修改的模块用新代码替换掉,而不需要整个页面重新加载;
原理:
dev-server 开启 WebSocket 服务器
监听源码文件变动
编译生成 hot-update.json 和 hot-update.js
用 WebSocket 通知浏览器
浏览器拉取更新文件
浏览器 HMR runtime 替换模块
如果模块用 module.hot.accept 声明了接受更新 → 局部替换
否则冒泡到父模块 → 最后可能触发页面刷新
webpack 如果热更新失败会怎么样?
如果模块没有 module.hot.accept() 或更新过程报错,HMR 会往父模块冒泡,看父模块能不能接收更新。冒泡到入口模块还不行,就会 fallback 到页面刷新。
webpack CSS 和 JS 的 HMR 有啥区别
CSS 比较简单,CSS-loader 内部已经实现了 HMR,不需要我们额外写代码。 JS 模块(尤其是 React/Vue 组件)需要用 module.hot.accept() 声明接受更新,否则就会触发全局刷新。在 React 项目里一般会用社区方案,比如 React Refresh(react-refresh-webpack-plugin),它在 Babel 和 Webpack 层面帮我们做了更细粒度的 HMR,包括状态保留、错误边界等。
webpack scope hoisting
scope hoisting 是 webpack 的内置优化,它是针对模块的优化,在生产环境打包时会自动开启。
在未开启 scope hoisting 时,webpack 会将每个模块的代码放置在一个独立的函数环境中,这样是为了保证模块的作用域互不干扰。
而 scope hoisting 的作用恰恰相反,是把多个模块的代码合并到一个函数环境中执行。在这一过程中,webpack 会按照顺序正确的合并模块代码,同时对涉及的标识符做适当处理以避免重名。
这样做的好处是减少了函数调用,对运行效率有一定提升,同时也降低了打包体积。
但 scope hoisting 的启用是有前提的,如果遇到某些模块多次被其他模块引用,或者使用了动态导入的模块,或者是非 ESM 的模块,都不会有 scope hoisting。
webpack - 联邦模块
在大型项目中,往往会把项目中的某个区域或功能模块作为单独的项目开发,最终形成「微前端」架构;
这涉及到很多非常棘手的问题:
- 如何避免公共模块重复打包
- 如何将某个项目中一部分模块分享出去,同时还要避免重复打包
- 如何管理依赖的不同版本
- 如何更新模块
webpack5 尝试着通过模块联邦来解决此类问题
暴露出去:
// webpack.config.js
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin');
module.exports = {
plugins: [
new ModuleFederationPlugin({
// 模块联邦的名称
// 该名称将成为一个全部变量,通过该变量将可获取当前联邦的所有暴露模块
name: 'home',
// 模块联邦生成的文件名,全部变量将置入到该文件中
filename: 'home-entry.js',
// 模块联邦暴露的所有模块
exposes: {
// key:相对于模块联邦的路径
// 这里的 ./now 将决定该模块的访问路径为 home/now
// value: 模块的具体路径
'./now': './src/now.js',
},
}),
],
};引用:
// webpack.config.js
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin');
module.exports = {
plugins: [
new ModuleFederationPlugin({
// 远程使用其他项目暴露的模块
remotes: {
// key: 自定义远程暴露的联邦名
// 比如为 abc, 则之后引用该联邦的模块则使用 import "abc/模块名"
// value: 模块联邦名@模块联邦访问地址
// 远程访问时,将从下面的地址加载
home: 'home@http://localhost:8080/home-entry.js',
},
}),
],
};
// src/bootstrap.js
// 远程引入时间模块
import now from 'home/now'webpack - splitchunksplugin 的使用场景及使用方法
公共模块:比如某些多页应用会有多个入口,从而形成多个 chunk,而这些 chunk 中用到了一些公共模块,为了减少整体的包体积,可以使用 splitchunksplugin 将公共模块分离出来。可以配置 minChunks 来指定被多少个 chunk 引用时进行分包
并行下载:由于 HTML5 支持 defer 和 async,因此可以同时下载多个 JS 文件以充分利用带宽。如果打包结果是一个很大的文件,就无法利用到这一点。可以利用 splitchunks 插件将文件进行拆分,通过配置 maxSize 属性指定包体积达到多大时进行拆分
介绍下 webpack - tree Shaking
tree-shaking 仅支持 ESM 的静态导入语法,对于 CMJ 或者 ESM 中的动态导入不支持 tree shaking。
具体流程主要分为两步:标记和删除
标记:webpack 在分析依赖时,会使用注释的方式对导入和导出进行标记,对于模块中没有被其他模块用到的导出标记为 unused harmony export
删除:之后在 Uglifyjs (或者其他类似的工具) 步骤进行代码精简,把标记为无用的代码删除。
webpack5 主要升级点
Webpack 5 的核心升级体现在三个方面:
- 构建性能
- 模块共享(微前端)
- 体积优化。 比如:模块联邦、文件系统缓存、增强的 Tree Shaking、弃用 Node polyfill、以及对 ESM 的全面支持。
webpack 的 module,bundle,chunk
Module(模块):你写的每一个文件(JS、CSS、图片等)
Chunk(代码块):Webpack 打包过程中生成的中间产物(一个或多个模块的集合)
Bundle(最终产物):Webpack 输出到磁盘的文件(就是 chunk 的打包结果)
- Module 是你项目中的每一个源文件,是构建的最小单元;
- Chunk 是 Webpack 根据模块依赖图组合出来的代码块(可以是入口块或异步块);
- Bundle 是将 Chunk 经过 loader/plugin 等处理后输出的最终静态资源文件。
简单来说:Module → Chunk → Bundle 是整个构建产物的生成过程。
npm vs yarn vs pnpm
npm 是老大哥,pnpm,yarn,cnpm,bower 这些东西的出现都是去为了弥补 npm 的不足或者是修复 npm 的缺陷 npm 这个团队反射弧有点长,修复的不及时,又或者是受到历史遗留的因素,比如在 yarn 推出 yarn.lock 后,npm 也推出了 package-lock.json, 再比如 npm3 也学习 yarn 扁平化 node_modules;
- npm 是 Node 自带的包管理器,但早期安装速度慢、容易产生版本冲突。
- yarn 是为了解决这些问题开发的,引入了并发安装和 lock 文件一致性。
目前我推荐并在项目中使用的是 pnpm,因为它的核心优势是使用了 硬链接的方式管理依赖,不仅安装速度更快,还大大节省磁盘空间,特别适合 monorepo 项目结构。
pnpm 的依赖隔离机制避免了“依赖地狱”问题,和微服务/多包管理天然契合
硬链接:是多个文件名指向同一个文件内容(inode) 软连接:快捷方式
npm:
- 安装结构扁平
- 多版本依赖可能冲突
- 下载 - 解压 - 放入 node_modules
- 重复依赖占空间最大
- 安装速度较慢
yarn:
- 安装结构扁平
- 多版本依赖可控性较好
- 下载 - 解压 - 放入 node_modules
- 重复依赖占空间较大
- 安装速度较快(并发)
pnpm:
- 安装结构为属性结构 + 硬链接
- 多版本依赖可控性最佳,隔离了依赖,防止版本污染
- 下载到缓存区 - 硬链接引用 - 更快更省空间
- 重复依赖占空间较小,多个项目共用一个依赖缓存
- 安装速度最快(缓存+并发+硬链接)
介绍下 npm link
本地开发多个包、调试 NPM 模块、做组件库/SDK 本地调试时经常用到的工具
用于在多个本地项目之间创建软链接(symlink)的命令
lib 项目里执行 npm link,app 项目中执行 npm link lib
npm link 后,为什么改了组件库代码,主项目没有自动热更新?
因为 link 创建的是符号链接,主项目仍然使用自己的构建缓存。
需要主项目配置 watch 包含 node_modules/my-lib(如 Vite/Vue CLI 中设置 optimizeDeps.exclude 或 webpack symlink 支持)
package.json 中的 script 执行后会发生什么
npm run dev 等同于 ./node_modules/.bin/vite
npm run 和直接运行命令有啥区别? npm 会添加 PATH、做日志包装、处理钩子等
npm i 的时候,npm 就帮我们把这种软连接配置好了,其实这种软连接相当于一种映射,执行 npm run xxx 的时候,就会到 node_modules/.bin 中找对应的映射文件,然后再找到相应的 js 文件来执行
pnpm 为什么快?
根本原因是它的依赖管理机制和文件存储方式完全不同。 pnpm 安装依赖时,不会每个项目都下载和解压一份依赖副本。 而是将所有依赖缓存到全局的内容可寻址存储仓库中,然后,在项目目录下用 硬链接(hard link) 的方式连接依赖文件。实际物理磁盘只存了一份内容,多项目共享。 这个存储位置可以用 pnpm store path 来获取到,内容是一堆 00,01 的文件夹,这是哈希前缀分片目录,用于分散文件数量,加快查找和文件系统访问效率。 pnpm 在缓存依赖包时,为每个依赖生成一个基于内容的哈希值(比如 SHA-512) 然后按这个哈希的前两位字符,决定放到哪个子文件夹下(比如 00, 01,一直到 ff,共 256 个)
pnpm 的关键是它使用了“硬链接 + 全局缓存”的方式安装依赖,避免重复解压和下载,相同依赖在多个项目中只存储一份,大大减少磁盘空间。 安装速度也明显快,依赖安装是并发执行的。同时 pnpm 对依赖版本控制更严格,防止因为平铺 node_modules 导致的问题,是现代项目和大型 monorepo 的首选。
介绍下 ESLint
预先配置好各种规则,通过这些规则来自动化的验证代码,甚至自动修复;
ESLint 的规则非常庞大,全部自定义过于麻烦,一般我们继承其他企业开源的方案来简化配置
这方面做的比较好的是一家叫 Airbnb 的公司,他们在开发前端项目的时候自定义了一套开源规则,受到全世界的认可
介绍下 husky 的原理
Git 提供了一种钩子机制,可以在特定的 Git 操作(如 commit、push)前后执行自定义脚本。
- pre-commit:在提交代码前执行。
- pre-push:在推送代码前执行。
- commit-msg:在提交信息被保存前执行。
husky 正是利用 Git 原生的钩子机制,在项目的 .git/hooks/ 目录中注入自定义脚本,通过软链接或 shell 脚本实现“提交前/提交后”的自动化任务。
当开发者执行 Git 操作时,Husky 会触发对应的钩子脚本。
Husky 会在这些钩子文件中调用用户定义的任务(如运行 Lint、测试等)。
如何在大型项目中优化 Lint 检查的性能?
Lint 检查耗时过长时如何优化?
- 使用 Lint-staged:只检查 Git 暂存区的文件,而不是整个项目。
- 按需检查:在 CI/CD 中,针对改动的文件运行 Lint,而不是全量检查。
- 缓存结果:使用 ESLint 的 —cache 参数缓存检查结果:
git rebase vs git merge
- git merge 是最常用的合并分支方式,它保留两个分支的历史并生成一个新的合并提交
- git rebase 是将当前分支的提交“迁移”到目标分支的最新提交之后,重写提交历史,保持提交线性、整洁。
两者的核心区别在于是否重写历史和提交记录是否线性。 在实际项目中,我一般在本地同步主分支代码时使用 rebase,避免产生无意义的 merge commit,而在多人协作时,合并功能分支到主干,通常使用 merge 保留完整的历史轨迹。
npx 指令
使用 npx 命令时,它会首先从本地工程的 node_modules/.bin 目录中寻找是否有对应的命令;如果将命令配置到 package.json 的 scripts 中,可以省略 npx;
当执行某个命令时,如果无法从本地工程中找到对应命令,则会把命令对应的包下载到一个临时目录,下载完成后执行,临时目录中的命令会在适当的时候删除
minify 主要做了什么工作
其实就是 AST => 小 AST
- 去除注释,
// 注释会被删掉 - 去除空格和换行,减少文件大小
- 变量名缩短,
function abcdef() → function a() - 常量折叠
2 + 2 → 4 - 死代码移除,移除未使用的函数或分支
前端工程化发展思路
什么是工程化?前端开发的管理工具集合就叫工程化,用以降低开发成本提升开发效率的
比如:
- 抽离公共组件,开发一个契合团队的前端脚手架
- 成员之间代码风格不一样,影响代码的维护和阅读?如何划分模块?如何进行单元测试?命名规范?版本控制?性能优化?
项目简单,团队规模小,一些现成的工具,官方的脚手架就可以解决问题,无法体现工程化的含义,截至目前前端有两百万个第三方库,绝大部分都和工程化相关
模块化:分解和聚合的思想,模块化解决的问题就是文件的:
- 全局污染问题
- 依赖混乱问题
提出了一些解决方案
- CJS
- CMD
- AMD
- UMD
- ESM
有了模块化和包管理,前端就有用了应对复杂项目的可能性
前端三剑客发展到现在很难适应复杂工程;三大语言在发明之初就没想到后续需要应对这么多复杂问题
三大语言的问题
js 语言问题:
- 兼容性(
- API 兼容 => polyfill => core-js
- 语法兼容 => syntax transform => babel,一般用到一些 preset,比如 @bable/preset-env
- 语言缺陷 => 语言增强 => 比如使用 ts
css 语言问题
- 语法缺失 比如循环 判断 拼接
- 功能缺失 比如颜色函数 数学函数 自定义函数
新语言 (scss less stylus) ===编译器===> css ===后处理器===> css
css —postcss 靠插件转换 -> css 不只是 后处理器,parser 可以自定义
开发维护的工程 ==构建工具==> 运行时需要的工程
介绍下 turbopack
Webpack 是 JS 社区最经典的构建器,但它存在性能瓶颈,尤其是在大型项目中构建缓慢。Turbopack 是由同一作者基于 Rust 重新设计的新一代构建工具,专为性能和模块热更新优化,目前是 Next.js 默认构建工具之一。虽然插件生态还不成熟,但未来在 React/Nex.js 方向有很大潜力。
Webpack 是“静态分析 + AST 构建依赖图”的架构,而 Turbopack 更偏向“lazy module graph + 编译时并发处理”。
Turbopack 的插件机制将支持 WASM,让构建生态更开放(
8.frame
Redux 是什么
Redux 是 React 核心成员 Dan 本人开发的状态管理库。 Redux 是基于函数式编程思想,集中式管理状态(MobX 是分散式管理)
- 单一数据源:整个应用的全局 state 被储存在一颗 object tree 中,并且这个 Object tree 只存在于为唯一一个 store 中。
- state 是只读的:唯一改变 state 的方法就是触发 action。
- 使用纯函数执行修改。
redux 核心流程:
UI 触发 → dispatch(action) → reducer(state, action) → 返回新 state → 通知订阅者更新 UI
- createStore 创建 store 数据管理库
- reducer 初始化,修改状态函数,定义修改规则
- getState 获取状态值
- dispatch 提交更新
- subscribe 变更订阅 订阅 state 改变之后要做的事情,一般是 组件更新
redux 核心 API:
- createStore() 创建 store 实例
- store.getState() 获取当前 state
- store.dispatch() 发送 action 触发 reducer 更新
- store.subscribe() 监听 state 变化
- combineReducers() 合并多个 reducer
redux Reducer 是什么?为什么必须是纯函数?
Reducer 是一个函数 (state, action) => newState 必须是纯函数,以保证:
- 相同输入一定得到相同输出(可预测)
- 易于测试和调试
- 支持时间旅行、撤销等功能
如何做异步请求?Redux 为什么默认不支持?
Redux 默认只支持同步 action,是为了保持 reducer 的纯粹性。 异步处理需借助中间件:
- redux-thunk 函数 action → 异步逻辑在 action 中
- redux-saga 使用 generator 写异步流程控制
- redux-observable 基于 RxJS,支持流式异步
Redux 中间件原理?如何实现一个日志中间件?
中间件本质是对 dispatch 的“增强链式调用”。
描述 Redux-Toolkit?
RTK 是 Redux 官方推荐的,开箱即用的一个高效的 Redux 开发工具库;(底层也只是封装了一层 Redux 而已;) 它包括几个实用程序功能,这些功能可以简化最常见场景下的 Redux 开发,包括配置 store,定义 reducer,不可变的更新逻辑,甚至可以立即创建整个状态的“切片 slice”,而无需手动编写任何 action ,creator 或者 action type,还自带了一些常用的 Redux 插件,例如用于异步逻辑的 Redux Thunk 等。
Redux、MobX、Recoil,解决什么问题?说一下分别的设计原理?有什么优势?
这三者都是状态管理库,当组件内部状态无法满足需求的时候,比如需要实现组件间的状态共享,此时就可以定义一些外部状态,同时还要保证外部状态更新了,组件也要更新,状态管理库就是做这件事情的。
Redux 和 Recoil 都是 fb 内部开发的状态管理库;按照出现时机来说,先后分别是 Redux,MobX,Recoil,这也基本决定了他们的市场占有率。
- Redux 基于函数式编程思想实现,集中式管理状态仓库,即一个项目通常只定义一个 store。
- MobX 是一个响应式状态管理库,实现之初参考了 Vue 的设计思想。与 Redux 不同,MobX 奉行分散式管理状态,即你可以定义多个 store,其主要实现思路是拦截状态的 get 与 set 函数,get 的时候把状态标记为可观察变量,set 是时候让组件更新。
Redux 和 MobX 本身都是 js 库,如果想要和 react 一起使用,经常需要再使用一个 react 的绑定库,如 react-redux,mobx-react。
- Recoil 与上面二者不同的是,Recoil 本身就是 React 的状态管理库,属于一体机,在 Recoil,状态定义的渐进式和分散式????
总结一下,Redux 是集中管理一个大状态,优点是比较专一,缺点是对于某些场景,比如不需要大量共享的时候,做不到特别灵活。而 MobX 和 Recoil 是可以分散式管理状态,因此相对 Redux 来说灵活性比较高。Recoil 由于又多了一层 selector,因此又可以渐进式定义状态,不过 fb 内部使用居多,目前还没发布正式版
zustand
mobX
DVA
DVA.js 是一个基于 Redux、Redux-saga 和 React-Router 封装的轻量级框架,目标是:
💡 简化 Redux 的使用,统一状态管理 + 异步处理 + 路由管理。
介绍下 vite
一句话:方案是迎合时代的;
vite 是一个新型的前端构建工具,在开发和构建中都显著提高了效率。核心思想是 bundleless,在开发阶段无需打包,而是利用浏览器原生 ESM 来进行模块加载; 前端模块化的演进过程大概是这样的:
- 15 年以前:早期面向文件,文件满天飞;
- 15-20:模块化渐渐被提出 讲一下模块化。..
- 20 年以后,esm(ECMAScript Module)在现代浏览器中得到广泛的支持 ,使得前端开发可以直接使用 import/export,而无需借助打包工具,浏览器通过
<script type='module'/>标签来加载 ESM,vite 正是利用了这一特性来实现无打包的开发环境, 比如早期 webpack 需要模块化规范支持,依赖分析后构建依赖图 deepGraph, bundleless 提倡少打包或者不打包(不打包基本不可能,esm 只是让 js 可以不打包,其他静态资源比如 css,png 等还是要打包)
在 vite 中
- 开发环境:js 不用打包直接出,应用代码资源比如 ts,jsx,tsx,vue,css,woff 等要打包
- 用 esbuild -> ts tsx jsx
- postcss -> css
- vite-plugin-xxx -> xxx
缺点:dts 文件需要自行处理,es5 以下
- 生产环境:产物构建使用 rollup 打包;
为什么 vite 开发环境用 esbuild,生产环境用 rollup
尤大佬在直播中有提到,其实也想用,但是 esbuild 目前对生产包支持不够健壮,很多配置无法通过 esbuild 实现。所以目前而言,Rollup 是一个好选择,虽然远比 esbuild 慢。
另外,可以用 esbuild 作为压缩器,替代 terser,这样会更快,但是包的体积可能会有 5% - 10% 左右的增长,看用户取舍。
esbuild 不支持 es5; 尽管 esm 得到了广泛的支持,但是由于嵌套导入会导致额外的网络往返,如果在生产环境中发布未打包的 esm,效率依然是低下的;生产环境还是要进行打包,做 tree-shaking,懒加载啊,chunk split,vite 目前的插件 api 与 esbuild 是不兼容的,Vite 目前仍然依赖 Rollup 插件 API 和基础设施(如模块依赖图、代码分割等),因此短期内不会切换到 esbuild 插件体系。
开发环境中可以使用 Rollup 插件,因为 Vite 的插件系统兼容 Rollup 插件 API。 大部分 Rollup 插件都可以正常工作,尤其是与模块解析、代码转换相关的插件。 但需要注意,某些依赖 Rollup 特定功能(如输出阶段)的插件可能无法在开发环境中使用
Vite 本地开发服务流程
- 项目初始化:读取并解析 vite.config.js 配置文件。
- 启动开发服务器:基于 express 启动 HTTP 服务器,
- ESM 支持:利用浏览器的原生 ESM 进行模块加载。
- 按需编译:实时编译请求的模块。
- 热模块替换 (HMR): 通过 WebSocket 实现模块的局部更新。
- Source Maps: 自动生成 Source Maps,便于调试。
Vite 构建流程
- 项目初始化:读取并解析 vite.config.js 配置文件。
- 入口解析:使用 Rollup 构建模块依赖图。
- 插件处理:通过插件系统进行代码转换、压缩和资源处理。
- Tree shaking: 移除未使用的代码。
- 代码拆分:将代码拆分成多个模块块,
- 生成输出:打包生成最终的输出文件。
- 资源优化:优化 CSS 和静态资源。
- 为静态资源添加内容哈希,便于缓存管理。
vite 中可以使用 CommonJS 吗
业务代码推荐使用 esm; 第三方库如果是 cjs ,会在预构建的时候转为 esm; 如果一定要在业务代码中使用 cjs,可以使用插件
vite 常见 hook?
- config 比如 alias
- configResolved 用于解析 vite 配置后调用
- configServe 给 dev server 添加自定义 middlew,比如 vite-plugin-mock
- transformIndexHtml 注入变量,用来转换 html 内容,比如 vite-plugin-html
- handleHotUpdate 执行自定义的 hmr
vite 为什么比 webpack 快?
webpack 以 entry 为起点做一个全量打包,中间涉及到构建 moduleGraph 这样的依赖分析,会进行大量的文件操作,文件内容解析,转换等
vite 会先使用 esbuild 进行预构建依赖,提前将第三方依赖转为 esm,dev server 会通过 middlewa 来对请求做拦截,对源文件做 resolve,load,transform,parse 等,再将转换之后的内容发送给浏览器
vite 预构建的目的
两个目的:
- 非 esm 的依赖转为 esm,开发环境将所有代码视为 esm
- 性能考虑,内部模块的 esm 将转为 单一模块进行加载,比如
import {debounce} from 'lodash-es',vite 不会去请求 600+个 lodash 内置模块,而是合并成一个单一的模块文件,
预构建的输出将会写入 node_modules/.vite 中,触发重新预构建的:
- lock 文件更改
- vite config 更改
- patch package 更改
- NODE_ENV 更改了才会触发重新预构建
已预构建的依赖请求使用 HTTP 头 max-age=31536000, immutable 进行强缓存
umi
Umi 做了很多编译时的事,如果你用过 umi,应该了解 src 下有个 .umi 临时目录,这里存放的文件本是需要开发者自己写的,现在由框架或插件在编译时自动生成。比如在 pages 目录下新建文件即是路由,新建 access.ts 文件即是权限,在 locales 目录下新建文件即是国际化语言,等等。 通过预打包,Umi 把依赖的 node 数从 1309 降到 314,这带来的不仅有安全和稳定,还有安装提速、node_modules 目录瘦身、命令行启动提速、无 peerDependency 警告等等。
Next.js
9.browser-network
介绍下 DNS 查找规则
- 浏览器里查找 chrome://net-internals/#dns, 如果有,直接用
- 操作系统里找 etc 目录下,本机 host 文件,如果有,直接用
- 本地域名服务器,如果有,直接用
- 向域名服务器发送请求
- 查询 根域名服务器 . 得到顶级域名服务器 IP
- 查询 顶级域名服务器 com. 如果有,直接用
- 两种情况
- 如果配置了 CDN,交给 CNAME 指向的 CDN 专用的 DNS 服务器
- 如果没配置 CDN,交给权威域名服务器 baidu.com.
本机和域名服务器一般都会有高速缓存,以减少查询次数和时间。
键入 URL 后,网络世界发生了什么
- URL 解析:判断输入的是一个合法的 URL 还是一个待搜索的关键词,并且根据你输入的内容进行自动完成、字符编码等操作
- 发起请求:接着发起真正的 URL 请求
- 查找缓存:如果浏览器本地缓存了这个资源,则会直接将数据转发给浏览器进程,如果没有缓存,则会查询 DNS 解析域名
- DNS 查找:首先先找浏览器有没有 DNS 缓存(之前有访问记录),如果有则 返回 ip
- 如果没有,则寻找本地的 host 文件,看看有没有域名记录,如果有则返回 ip
- 如果本地 host 没有则直接向 DNS 服务器请求,如果还是没有,继续向上 DNS 服务器请求,直至返回,拿到 ip 地址
- 三次握手:向服务器发送 http 请求之前,先要和服务器建立 tcp 连接,其实就是三次握手
- 发送 http 请求:连接建立成功后,就可以发送 http 请求数据了
- 浏览器渲染:浏览器渲染
介绍下三次握手
- seq:序列号,随机生成
- ack:确认号,seq+1
- ACK:确认序列号有效
- SYN:发起新连接 主要流程:在 HTTP 请求之前,可以看到三次 tcp 连接
- 客户端向服务端,seq=clientid,SYN;
- 服务端向客户端,seq=serverid,ack=clientid+1,SYN,ACK
- 客户端向服务端,seq=clientid+1,ack=serverid+1,ACK 为什么第三次也要发 seq 呢?答案是每个 tcp 连接都要有序列号,以保证顺序控制和流量控制
TCP 有个重要的点就是可靠性,发送出一条消息,一定要等到对面说我收到了,才算发成功;
为什么需要握手?需要同步序列号,TCP 三次握手可以确保双方都具备发送和接收数据的能力。
为什么挥手是四次,握手是三次?因为握手的时候不需要发数据,挥手的时候可能还有数据正在发送(半连接状态);但握手的时候是不允许有所谓半建立的状态的,这是 TCP 的规范,所以握手的第二次中,serve 在回 ACK 的时候必须把 SYN 发过来;
介绍下四次挥手
- seq:序列号,随机生成
- ack:确认号,seq+1
- ACK:确认序列号有效
- SYN:发起新连接
- FIN:完成 主要流程:(假设是客户端发起的
- 客户端向服务端:seq=clientid,FIN,客户端进入 FIN_WAIT_1,
- 服务端收到后,向客户端:ack=clientid+1,ACK,服务端进入 CLOSE_WAIT,
- 客户端收到后,客户端进入 FIN_WAIT_2(如果有未完成的请求或者别的响应,在这个阶段要完成,直到所有都处理完后,发起第三次挥手)
- 服务端向客户端:seq=serverid,ack=clientid+1,ACK,FIN,服务端进入 LAST_ACK
- 客户端收到后,向服务端发送:seq=clientid+1,ack=serverid+1,ACK,之后进入 TIME_WAIT 状态
- 服务端收到后,服务端进入 close
- 客户端在 2msl 后 自动进入 close
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。 2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK 没有传输到服务端,客户端又接收到了服务端重发的 FIN 报文,那么 2MSL 时间将重新计时。
为什么需要四次?
关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
服务端收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接;
浏览器是如何渲染页面的?
当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。
在事件循环的机制下,渲染主线程取出消息队列中的渲染任务,开启渲染流程 整个渲染流程分为多个阶段分别是:
- 解析 Html => DOM 树,CSSOM 树
- 样式计算 => 带有样式的 DOM 树
- 布局 => lauoyt tree
- 分层
- 绘制,生成绘制指令
- 分块
- 光栅化
- 画
每个阶段都有明确的输入输出,这样渲染流程就形成了一套组织严密的生产流水线
渲染的第一步是 解析 HTML 解析过程中遇到 CSS 就解析 CSS,遇到 JS 执行 JS。为了提高效率,浏览器在开始解析前,会启动一个 预解析线程,率先下载 HTML 中外部 CSS 和 JS 文件。
如果主线程解析到 link,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在 预解析线程 中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。
如果主线程解析到 script,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML,这是因为 JS 代码的执行过程会可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 的根本原因。
第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式,内部样式,外部样式,行内样式均会包含在 CSSOM 中。
渲染的下一步是 样式计算
主线程遍历得到的 DOM,依次为树中的每个节点计算出它最终的样式,称之为样式计算。 在这一步,很多预设值会变成绝对值,比如 red 会变成 rgba(255,0,0); 相对单位会变成绝对单位,比如 em 会变成 px
这一步结束后,会得到一颗带有样式的 DOM 树
接下来是 布局,布局完成后会得到布局树
布局阶段会依次遍历 DOM 树的每一个节点,计算每个节点的几何信息,例如节点的宽高,相对包含块的位置。大部分时候,DOM 树和布局树并非一一对应。
下一步是 分层
主线程会使用一套复杂的策略对整个布局树进行分层。
分层的好处在于,将来某一层改变后,仅会对该层进行后续处理,从而提升效率。
滚动条,堆叠上下文,transform,等样式或多或少的影响分层结果,也可以通过
will-change属性更大程度影响分层效果。再下一步是 绘制
主线程会为每个层单独产生一套绘制指令,用于描述这一层的内容该如何画出来。
完成绘制后,主线程会将每个图层的绘制信息提交给合成线程。剩余工作由合成线程完成。
再下一步是 分块
合成线程首先对每个图层进行分块,将其划分为更多的小区域。(分多个线程来完成分块工作)
分块完成后,进入 光栅化 阶段 合成线程会将块信息交给 GPU 进程,以极高的速度完成光栅化。
GPU 进程会开启多个线程来完成光栅化,并且优先处理靠近视口的块。
光栅化的结果就是一块一块的位图。
最后一个阶段就是 画
合成线程拿到每一层,每个块的位图后,生成一个个指引(quad)
指引为表示出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转,缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是
_transform效率高的本质原因合成线程会把 quad 交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像。
介绍下 http 缓存
浏览器缓存策略分为两种:强缓存和协商缓存。
强缓存这个”强”实际形容得不太恰当,强缓存也称为本地缓存(local cache),意味着浏览器在一定时间内直接从本地缓存中读取资源,而不去服务器请求;
协商缓存,顾名思义就是浏览器和服务端有商有量,每次请求资源时,浏览器都会与服务端进行通信,根据服务器的响应决定是否使用本地缓存(强缓存)
- 浏览器在加载资源时,根据 request header 的 Expires(http1.0) 和 Cache-Control(http1.1) 判断是否命中强缓存,是则直接从本地缓存读取资源,返回 200 from memory/disk cache,不会发请求到服务器。
- 如果没有命中强缓存,浏览器一定会发送一个请求到服务器,通过 Last-Modified(http1.0) 和 ETag(http1.1) 验证资源是否命中协商缓存,如果命中,则返回 304 读取缓存资源
- 如果前面两者都没有命中,直接从服务器请求加载资源
强缓存通过 expired(少用)和 cache-control 控制 由于 expired 服务器的时间和客户端的时间不一样的情况下,所以 HTTP1.1 提出 cache-control
res.setHeader("Cache-Control", "no-store, max-age=60"); max-age 单位是秒
- public 表示可以被浏览器和代理服务器缓存,存在 Authorization 头时默认为 private
- private 只让客户端可以缓存该资源;代理服务器不缓存
- no-cache 跳过设置强缓存,但是不妨碍设置协商缓
- no-store 禁止使用缓存,每一次都要重新请求数据
协商缓存是利用的是 Last-Modified/If-Modified-Since 和 ETag/If-None-Match 这两对标识来管理的 Last-Modified/If-Modified-Since 的局限性是单位只到秒,
项目中有配置到缓存吗
强缓存适用于静态资源(如 JS、CSS、图片),结合文件名哈希确保更新。 协商缓存适用于动态资源(比如接口数据),通过 ETag 或 Last-Modified 减少服务器压力。
用户行为对浏览器缓存的影响
- 打开网页,地址栏输入地址: 查找 disk cache 中是否有匹配。如有则使用;如没有则发送网络请求。
- 普通刷新 (F5):因为 TAB 并没有关闭,因此 memory cache 是可用的,会被优先使用(如果匹配的话)。其次才是 disk cache。
- 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有 Cache-control:no-cache(为了兼容,还带了 Pragma:no-cache), 服务器直接返回 200 和最新内容。
更新强缓存有哪几种方式
- 修改文件名
- 修改 url 参数,版本号或者时间戳
- service worker???
CDN 回源是什么
CDN 回源包括回源地址和加速域名。常规的 CDN 都是回源的。即当有用户访问某一个 URL 的时候,如果被解析到的那个 CDN 节点没有缓存响应的内容,或者是缓存已经到期,就会回源站去获取。如果没有人访问,那么 CDN 节点不会主动去源站拿的。
CDN 的优势
异地容灾,负载均衡
跨域是什么,如何解决
跨域是指浏览器的同源策略限制了从一个源(协议、域名、端口)加载或访问另一个源的资源。
如何解决跨域问题?
- CORS(跨域资源共享)
- JSONP
- 代理服务器
- Nginx 反向代理
- PostMessage
什么是 CORS?如何工作?
- CORS (cross-origin resource sharing)是一种跨域资源共享机制,允许浏览器向不同源的服务器发起请求。CORS 是基于 http1.1 的一种跨域解决方案。
- 浏览器发送请求。
- 服务端返回
Access-Control-Allow-*响应头。 - 浏览器根据响应头决定是否允许跨域访问。
JSONP 的原理是什么?
- JSONP 利用
<script>标签不受同源策略限制的特点,通过动态创建<script>标签加载资源。 - 服务端返回一个包含回调函数的 JSON 数据。
- 优点:兼容性好,简单易用。
- 缺点:只支持 GET 请求,存在安全风险。
为什么开发环境不会跨域?**
浏览器向本地开发服务器(如 http://localhost:3000)发送请求。 本地开发服务器将请求转发到目标服务器(如 https://api.example.com)。 由于代理服务器和目标服务器之间没有同源限制,跨域问题被绕过。
跨域时如何携带 Cookie?
- 前端设置:
fetch('https://example.com/api', { credentials: 'include' }); - 服务端设置:
res.setHeader('Access-Control-Allow-Origin', 'https://yourdomain.com'); res.setHeader('Access-Control-Allow-Credentials', 'true');
跨域时如何处理 WebSocket?
- WebSocket 不受同源策略限制,但需要服务端支持。
- Nginx 配置:
location /ws/ { proxy_pass http://localhost:3000; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; }
HTTP 常见状态码
- 1xx 信息响应:表示请求已被接受,需要继续处理。比如
- 100(Continue) 表示到目前为止一切正常,客户端可继续请求。
- 101(Switching Protocol) 表示服务器同意客户端的协议切换
- 2xx 成功:表示请求已成功接收、理解、并处理。
- 200Ok 表示请求成功,服务器返回请求的数据;
- 201Created 请求成功且资源已被创建,常用于 POST/PUT;
- 202Accepted 请求已接受,但尚未处理;
- 204 表示请求成功但没有内容返回,通常用于 Delete 请求;
- 3xx 重定向:表示要完成请求,需要进行进一步操作。比如
- 301Move Permanently 表示请求的资源已被永久移动到新位置,301 和 302 的 response header 都有 location 字段,浏览器会自动跳转;
- 302Found 请求的资源暂时被移动到新的位置,响应中也会包含新的 URL;
- 304NOT Modified 表示资源没修改,客户端可以使用缓存的版本
- 4xx 客户端错误:表示请求包含语法错误或无法完成。比如
- 400Bad Request 表示服务器无法理解请求的数据格式;
- 401Unauthorized 表示请求未授权,需要进行身份验证;
- 403Forbidden 表示理解请求但拒绝执行;
- 404Not Found 表示请求的资源不存在;
- 405Method Not Allowed 表示请求方法不被服务器允许;
- 408Request Timeout 表示服务器去等待客户端发送请求超时;
- 409Conflict 表示请求与资源的当前状态冲突;
- 410Gone 表示请求的资源永久删除了;
- 5xx 服务器错误:表示服务器在处理请求时发生错误。比如
- 500Internal Server Error 表示服务器内部错误;
- 501Not Implemented 表示服务器不支持请求的功能;
- 502Bad Gateway 表示服务器作为网关或代理,从上游服务器收到了无效响应;
- 503Service unavailable 表示服务器暂不可用,通常是由于维护或过载;
- 504Gateway Timeout 表示服务器作为网关或者代理,未能及时从上游服务器接收响应
说一下 http 演变
HTTP1: 问题:无法复用 TCP 连接;连接的建立和销毁都会占用服务器和客户端的资源,造成内存资源的浪费
HTTP1.1: 改进:
- 长连接 connect: keep-alive, 多次请求响应可以共享同一个 TCP 连接,这不仅减少了 TCP 的握手和挥手时间,同时可以充分利用 TCP「慢启动」的特点,有效的利用带宽。 如何关闭连接:
- 客户端在某一次请求中设置了 Connection:close
- 在没有请求时,客户端会不断对服务器进行心跳检测(一般每隔 1 秒)。一旦心跳检测停止,服务器立即关闭 TCP
- 当客户端长时间没有新的请求到达服务器,服务器会主动关闭 TCP。运维人员可以设置该时间
- 管道传输:(不常用),只要第一个请求发出去了,不必等其回来,就可发第二个请求。
- 缓存处理:新增响应头 cache-control,用于实现客户端缓存。
- 断点传输:在上传/下载资源时,如果资源过大,将其分割为多个部分,分别上传/下载,如果遇到网络故障,可以从已经上传/下载好的地方继续请求,不用从头开始,提高效率
问题:
- 队头阻塞并没有解决(发生在服务器), 由于多个请求使用的是同一个 TCP 连接,服务器必须按照请求到达的顺序进行响应
- header 很大,浪费
- 请求只能从客户端开始,服务器只能被动响应
所以 HTTP1.1 在优化手段上,我们一般建议
- 减少文件数量,从而减少队头阻塞的几率;
- 通过开辟多个 TCP 连接,实现真正的、有缺陷的并行传输,浏览器会根据情况,为打开的页面自动开启 TCP 连接,对于同一个域名的连接最多 6 个,如果要突破这个限制,就需要把资源放到不同的域中
HTTP2.0: 基于 https 上;
改进:
- 二进制分帧:每个传输单元称之为帧,而每一个请求或响应的完整数据称之为流,每个流有自己的编号,每个帧会记录所属的流。
- 多路复用:基于二进制分帧,在同一域名下所有访问都是从同一个 tcp 连接中走,并且不再有队头阻塞问题,也无须遵守响应顺序
- 头部压缩:
- 对 header 编号,存入静态表,传输编号即可
- 静态表里没有的,还是直接发送,但会添加到动态表中
- 两张表都没有的,会进行 Huffman 编码压缩后再传输,同时添加到动态表中
- 服务端主动推送
为什么 HTTP1.1 不能实现多路复用(腾讯)
HTTP/1.1 的传输单元是整个响应文本,因此接收方必须按序接收完所有的内容后才能接收下一个传输单元,否则就会造成混乱。而 HTTP2.0 的传输单元更小,是一个二进制帧,而且每个帧有针对所属流的编号,这样即便是不同的流交替传输,也可以很容易区分出每个帧是属于哪个流的。
简单讲解一下 http2 的多路复用(网易)
在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。 帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。 多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
http1.1 是如何复用 tcp 连接的?(网易)
客户端请求服务器时,通过请求行告诉服务器使用的协议是 http1.1,同时在请求头中附带 connection:keep-alive(为保持兼容),告诉服务器这是一个长连接,后续请求可以重复使用这一次的 TCP 连接。
这样做的好处是减少了三次握手和四次挥手的次数,一定程度上提升了网络利用率。但由于 http1.1 不支持多路复用,响应顺序必须按照请求顺序抵达客户端,不能真正实现并行传输,因此在 http2.0 出现之前,实际项目中往往把静态资源,比如图片,分发到不同域名下的资源服务器,以便实现真正的并行传输。
https
HTTPS 无非就是 HTTP + SSL/TLS,而 SSL/TLS 本质上在解决如何协商出安全的对称加密密钥这一问题,以利用此密钥进行后续的通讯;
如何协商出安全可信任的对称加密密钥🔑? 答案是 server 和 client 之间,使用非对称加密来传输对称加密密钥;
那么如何传输非对称加密的公钥给客户端呢?答案是用 Ca 证书
- 浏览器告知加密方式
- 服务器选择加密方式并返回 CA 证书
- 浏览器收到证书后使用系统内置 CA 证书中的公钥来解密得到的摘要 B,hash CA 明文的其他信息得到 摘要 A,如果 摘要 A === 摘要 B,就认为校验通过,可以认为这个 CA 证书里服务器的公钥是安全的
- 用这个公钥加密了一个对称加密的密钥出来给到服务器
- 服务器用私钥解密,就得到了对称加密的密钥
- 此后就用这一密钥进行数据传输
HTTPS 如何防止重放攻击?
加随机数/时间戳等
介绍下 Https 的中间人攻击
针对 HTTPS 攻击主要有 SSL 劫持攻击和 SSL 剥离攻击两种。
SSL 劫持攻击是指攻击者劫持了客户端和服务器之间的连接,将服务器的合法证书替换为伪造的证书,从而获取客户端和服务器之间传递的信息。这种方式一般容易被用户发现,浏览器会明确的提示证书错误,但某些用户安全意识不强,可能会点击继续浏览,从而达到攻击目的。
SSL 剥离攻击是指攻击者劫持了客户端和服务器之间的连接,攻击者保持自己和服务器之间的 HTTPS 连接,但发送给客户端普通的 HTTP 连接,由于 HTTP 连接是明文传输的,即可获取客户端传输的所有明文数据。
Cookie 为了解决什么问题
Cookie 是一种存储在浏览器中的小文件,用户存储网站的一些信息。通过 Cookie,服务器可以识别用户并保持会话状态,实现会话保持。
解决问题: Cookie 诞生的主要目的是为了解决 HTTP 协议的无状态性问题。HTTP 协议是一种无状态的协议,即服务器无法识别不同的用户或跟踪用户的状态
OSI 七层模型 应表会 传 网 数 物
OSI 算是一个参考的理论模型,TCP/IP 四层是实施的模型;
从上到下分别为:应用层、传输层、网络层、数据链路层、物理层。在发送消息时,消息从上到下进行打包,每一层会在上一层基础上加包,而接受消息时,从下到上进行解包,最终得到原始信息。
- 应用层:HTTP,FTP,DNS,这一层叫报文
- 表示层:JEPG,ASCII,可以理解为翻译官,这一层叫报文
- 会话层:SSL/TLS,这一层叫报文
- 传输层:TCP,UDP,主要定义端口号,这一层叫数据段
- 网络层:IP,ICMP,主要做寻址和路由,这一层叫数据包
- 数据链路层:进行硬件地址的寻址,将比特组合成字节进而组合成帧,这一层叫数据帧
- 物理层:电/光/无限波,这一层叫比特流
介绍下 SSE
Server Sent Event,基于 HTTP 的,服务器主动向客户端推送数据的技术。
客户端发起请求,服务端可以实时的向客户端发送消息;相比于 websocket ,SSE 算是个 单工通讯,客户端只能发一次,之后都由服务端推送,websocket 是双工的,两端都可以发消息。
后端设置接口的 content-type 为 text/event-stream,前端 new EventSource 开启一次 SSE,然后监听 message(默认的,后端可修改)事件即可拿到数据
chatGTP 网页就利用了 SSE 技术,打字效果;
GET vs POST
从 http 协议的角度来说,GET 和 POST 它们都只是请求行中的第一个单词,除了语义不同,其实没有本质的区别。
之所以在实际开发中会产生各种区别,主要是因为浏览器的默认行为造成的。
受浏览器的影响,在实际开发中,GET 和 POST 有以下区别:
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST 请求的传递信息量是没有限制的,适合传输大量数据。
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用 GET 请求,至少不应该放到 path 中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示。
- GET 请求的地址可以被保存为浏览器书签,POST 不可以
websocket 是什么
单个 tcp 连接上的全双工通信的协议,常用于聊天,多人协作啊, 后端可用 ws 库,创建一个 ws 服务,然后监听 Connection 事件,获得是否连接成功的信息,以及所对应的 socket ,给 socket 添加 message 监听事件,就可以收到来自客户端的消息推送,按需将消息用广播出去,可以通过 ws.client 得到已连接的所有客户端, 前端直接用 new WebSocket 实例化一个 ws 对象,然后添加事件监听,比如 message 事件等;
websocket 握手
首先,客户端若要发起 websocket 连接,首先必须向服务器发送 http 请求以完成握手,请求行中的 path 需要使用 ws: 开头的地址,请求头中要分别加入
- upgrade、
- connection、
- Sec-WebSocket-Key、
- Sec-WebSocket-Version 标记
然后,服务器收到请求后,发现这是一个 websocket 协议的握手请求,于是响应行中包含 Switching Protocols,同时响应头中包含
- upgrade、
- connection、
- Sec-WebSocket-Accept 标记
当客户端收到响应后即可完成握手,随后使用建立的 TCP 连接直接发送和接收消息
心跳监测
由于 socket 长时间不使用,或者因为网络波动,弱网模式,是有可能断开的,心跳检测可用来进行保活。
一般是由客户端每隔大概 5s 向服务器发起 ping 包,服务器回应 pong,如果在一段时间内未收到服务端的 pong,则断开连接或者尝试重连,服务端也是同理,如果长时间未收到客户端的 ping,可用主动关闭连接
navigator sendBeacon
除了 ajax,fetch,sse,websocket jsonp 之外,sendBeacon 也可以发送网络请求;使用的是 h5 新增的 ping 请求
- 心跳检测
- 埋点
- 发送用户反馈
优点:不受页面卸载的影响
缺点:受限于广告屏蔽插件,支持的数据类型有限,只有 text,blob,formdata 等,只能发送 post 请求,64kb 上限的数据
TCP vs UDP
UDP(User Datagram Protocol),用户数据包协议,是一个简单的面向数据报的通信协议,即对应用层交下来的报文,不合并,不拆分,只是在其上面加上首部后就交给了下面的网络层
也就是说无论应用层交给 UDP 多长的报文,它统统发送,一次发送一个报文;
TCP(Transmission Control Protocol),传输控制协议,是一种可靠、面向字节流的通信协议,把上面应用层交下来的数据看成无结构的字节流来发送
可以想象成流水形式的,发送方 TCP 会将数据放入“蓄水池”(缓存区),等到可以发送的时候就发送,不能发送就等着,TCP 会根据当前网络的拥塞状态来确定每个报文段的大小
TCP 报文首部有 20 个字节,额外开销大;
区别如下:
TCP 是面向连接的协议,建立连接 3 次握手、断开连接四次挥手,UDP 是面向无连接,数据传输前后不连接连接,发送端只负责将数据发送到网络,接收端从消息队列读取
TCP 提供可靠的服务,传输过程采用流量控制、编号与确认、计时器等手段确保数据无差错,不丢失。UDP 则尽可能传递数据,但不保证传递交付给对方
TCP 面向字节流,将应用层报文看成一串无结构的字节流,分解为多个 TCP 报文段传输后,在目的站重新装配。UDP 协议面向报文,不拆分应用层报文,只保留报文边界,一次发送一个报文,接收方去除报文首部后,原封不动将报文交给上层应用
TCP 只能点对点全双工通信。UDP 支持一对一、一对多、多对一和多对多的交互通信
HTTP3.0 改用 QUIC(基于 UDP 的),QUIC 自己实现了一个层,它提供了数据包重传、拥塞控制、调整传输节奏(pacing)以及其他一些 TCP 中存在的特性。从而保证准确性与可靠性
介绍下 XSS (Cross-Site Scripting)
跨站脚本攻击
- 反射型 比如电子邮件中,诱使用户去访问一个包含恶意代码的 URL,可能包含恶意代码,通常出现在网站的搜索栏、用户登录口等地方,常用来窃取客户端 Cookies 或进行钓鱼欺骗。
- 存储型 常见于由社区驱动的内容网站,比如博客评论,留言板等
- DOM 型 innerHtml,eval,v-html,location
如何预防:
- 用 xss 漏洞扫描工具提前发现漏洞
- 输入过滤
- 输出转义
- CSP(Content Security Policy)
- default-src
- script-src
- style-src
<meta http-equiv="Content-Security-Policy" content="default-src 'self' cdn.example.com; script-src 'self'; style-src 'self' fonts.google.com" />
介绍下 CSRF (Cross-Site Request Forgery)
跨站请求伪造:CSRF 是利用浏览器自动携带 Cookie 特性,攻击者诱导用户发起伪造请求,造成非法操作。 预防措施包括:
- 使用 CSRF Token,验证请求中的 Token 是否匹配;
- 设置 Cookie 的 SameSite 属性;
- 验证 Referer 或 Origin 请求头;
- 双重提交 Cookie 等方式,从而有效防止 CSRF 攻击。
介绍下 JWT (JSON Web Token)
由三部分组成:用 点 分割开
- 头部:类型和签名算法,base64
- payload:用户信息(不能包含敏感信息),base64
- 签名:加密上述两个数据得到的,用于验证完整性和真实性,加密后再 base64
介绍下 Google reCAPTCHA
reCAPTCHA 会分析用户的行为(如鼠标移动、点击模式等)来判断是否为人类。如果行为可疑,会触发验证挑战(如选择图片、输入验证码等),reCAPTCHA v3 会为每个请求生成一个评分(0.0 到 1.0),表示用户行为的可信度
介绍下加密
密钥
密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
对称加密:又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有 DES、3DES、TDEA、Blowfish、RC5 和 IDEA。
非对称加密:也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
摘要:摘要算法又称哈希/散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用 16 进制的字符串表示)。算法不可逆。
10.infrastructure
npm 私服
项目中使用 Verdaccio 搭建了 npm 私服,主要用于缓存外部包和发布公司内部的组件库和工具库,提高构建效率、保障发布安全。我们通过配置 config.yaml 实现了权限控制,结合 CI/CD 流程实现了私有包的一键发布。日常开发中通过 .npmrc 设置私服源,实现透明化安装。
自己封装 ahri-ui?
ANTD 适合中后台的通用组件库,这些组件基本可以满足一个系统 80% 以上的页面搭建诉求;
优:组件非常全面,样式效果也不错,
缺:框架自定义程度低,默认 UI 风格修改困难
因此也应公司业务需求,我们组织开发了一套改版的 antd,叫 ahri-ui;开发过程中通过对 antd 源码的阅读,我得到了如下的一些经验。
- 结构清晰:每个 UI 组件都是完整的模块,都有自己独立的目录结构
- 组件分离:每个 IO 组件都是可以被独立引用的,按需引入的思想,减少业务方文件大小
- 测试覆盖:antd 通过 jest 覆盖了每个组件的测试
Docker
docker: 仅仅几百兆,一台机器大约可部署 2000 个 docker,实现轻量级的集群;只要做好一个环境,所有环境就可以实现集群部署; 所有的项目最终都要布署到线上才能对外提供服务,现在主要使用 docker 直接启动镜像的方式,Docker 是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行,常用命令有 docker build ,docker pull/push ,docker run -p,docker tag 等等,前端镜像部署的话,在 dockerFile 中 基于 nginx,我们将 nginx.conf(做一些压缩,设置日志格式等等) , app.conf(做一些反向代理的配置)复制到 对应的环境中,再将 dist 复制到 根目录下,然后,即可打包制作镜像;
实际使用场景通常是跟 CI/CD 结合,以每个 git commit 作为版本号,有问题的时候就回滚;
CI/CD
我们是使用 GitLab 问题(Issues)、史诗(Epics)和里程碑(Milestones)进行项目组合和项目管理,他同是也支持 cicd,(虽然相较于 Jenkins 这个老大哥,他还是个新手)使用 YAML 文件来描述整个管道。
只需要在仓库根目录下创建。gitlab-ci.yml 文件,并配置 GitLab Runner;
每次提交的时候,gitlab 将自动识别到。gitlab-ci.yml 文件,
stage:build | lint | dockerize | deploy
12.teamwork
技术分享
比如帮助团队了解某个新技术或解决项目中的技术难点。然后,我会选择一个主题,比如最近项目中用到的性能优化方法,并准备结构化的内容,包括背景、核心原理、实践案例和总结。我会通过在线工具进行演示,并在分享过程中引导团队提问和讨论。最后,我会收集团队的反馈,改进我的分享方式,同时将内容整理成文档,方便后续查阅。
技术选型怎么做
- 在技术选型时,我会首先明确项目的需求和目标,包括功能需求、性能要求和团队的技术能力。
- 我会列出候选技术方案,会考虑项目的复杂性、团队的熟悉程度以及社区支持。
- 我会对比这些方案的优缺点,并进行小规模验证(POC),确保技术能够满足需求。
- 我会与团队讨论并达成一致,选择最适合当前项目的技术栈,同时为未来的扩展性留有余地。
如何做 code review?发现过哪些严重的问题?如何让 Code Review 更高效
流程是:两人及以上小伙伴的批准,每个合并请求指派人是团队小组长,review 是除小组长之外的另一个小伙伴,小组长和这个小伙伴都通过方可;
审阅: 实际工作场景会遇到一些开放式或紧急的提交,良好的 CodeReview 习惯自然是要严谨一些,讨论清楚再通过,并且要及时反馈。但某些比较紧急的提交就要区别对待了,更好的态度是在实践中灵活对待,但及时紧急通过了,也要保证问题在后续得以修复,比如在代码中留一些 “TODO” 或 “FIXME” 的标记,写上对应的负责人与预期解决时间;
代码自动化工具的目的,很大一部分也是为了保证代码一致性,从而降低 CodeReview 成本,也减少不重要的评论信息出现,让 CodeReview 尽可能反馈逻辑问题而不是格式问题。
具体:大部分问题通过 eslint 和 prettier 解决
- 代码质量与可读性(基础)
- 变量/函数命名是否清晰、语义化?是否使用了缩写或拼音?
- 是否存在 magic number?是否应该提取为常量?
- 注释是否必要、准确?是否用注释掩盖糟糕代码?
- 组件设计和封装粒度
- 是否符合“单一职责”?组件是否拆分合理?
- 是否存在 props 过多/重复逻辑/过度封装等设计问题?
- 是否有复用价值?能否提取为 hooks 或通用组件?
发现过哪些严重的问题?
- props drilling 过深 → 用 context 或状态管理;
- 使用了过时的 UNSAFE_componentWillMount → 建议迁移到 hooks;
- 把 UI 和数据强耦合 → 拆为 UI + 容器组件;
- 没有处理异常状态 → 增加 loading/error 状态。
如何让 Code Review 更高效 细节建议请写清楚 rationale(原因),比如:
“建议将这个 axios.post() 封装为 service 层,避免重复调用逻辑扩散。”
别只说“不好”,要建议替代方案
“这里的 loading 建议用全局 loading store 管理,更便于后期维护。”
平衡“完美主义”与“性价比”,不是每一行都要完美,而是找准重点。
什么时候会考虑封装组件,封装的时候会怎么思考
什么时候考虑封装
- 多个页面/模块中甚至多个项目重复出现的 UI 或逻辑
- 复杂组件需要统一交互和行为管理
- 抽象业务组件以复用逻辑
封装时候怎么思考
- 哪些部分是“变”的,哪些是“稳定”的?保持灵活性:不将所有细节写死
- API 是否简洁易用?命名是否语义化?是否符合直觉?能否一眼看出如何使用?- props 是否冗余或混乱?
- 是否考虑扩展性?将来变化是否好加?
- 边界情况和异常处理
我会优先识别出重复度高、逻辑固定的部分,抽象为通用组件。在封装时,我会平衡使用成本与扩展性,关注哪些 props 是稳定的,哪些可以通过 render-props 留给使用者自定义,同时保障类型安全和边界处理。
13.react
react 的渲染分哪几个阶段
React 渲染主要分为两个阶段:Render 阶段和 Commit 阶段。Render(也叫 reconciliation 阶段)
render 阶段里面会经由调度器和协调器处理,此过程是在内存中运行,是异步可中断的。这个阶段的产物是生成 effect list(副作用列表,记录要做哪些更新)。
commit 阶段会由渲染器进行处理,根据副作用进行 UI 的更新,此过程是同步不可中断的,否则会造成 UI 和数据显示不一致。这个阶段的产物是更新真实 DOM,执行副作用(如 useEffect、生命周期)。
介绍一下 scheduler
React 的目标之一是实现高性能的 UI 更新,尤其是在复杂页面和慢设备上。为了避免一次性处理大量更新造成主线程阻塞、掉帧卡顿,React 从 16 开始引入了 Fiber 架构,而 Scheduler 正是这套架构背后负责“任务优先级控制和调度”的核心模块。
scheduler 是 React 独立出来的一个调度器库,用于按优先级分配和安排任务执行时间,实现任务的中断、恢复与抢占,确保更紧急的任务优先执行,提升交互体验。
是 render 的第一阶段
- 分配优先级:React 定义了多个优先级(如 Immediate, UserBlocking, Normal, Idle),由 scheduler 控制任务处理顺序。
- 可中断渲染:messageChannel 创建宏任务,任务可以在需要时中断,让出主线程
- 时间切片:把大的任务拆成小的任务,每帧执行一部分,避免主线程卡顿
- 任务过期控制:Scheduler 会跟踪任务是否过期,决定是否立即同步执行
核心数组:
- taskQueue 普通任务,
- timerQueue 延时任务,advancerTimer 方法:遍历整个 timerQueue,查看是否有已经过期的方法,如果有,不是说直接执行,而是将这个过期的方法添加到 taskQueue 里面
核心算法:
小顶堆算法 始终取出优先级最高的任务
描述下 React 的任务调度机制?
React 中实现了一个单线程任务调度器,使用最小堆的数据结构管理这些任务,每次来了新的任务都会先放入最小堆任务池中。 在时间切片内,循环执行任务,如果超时,那么再次重新调度。这样就避免了一些高优先级任务因为来得晚而迟迟得不到处理的问题,从而提升页面流畅度。 任务执行的顺序取决于他们的优先级与过期时间,所以值越小,证明这个任务越应该先被执行,而单线程任务调度器每次只能执行一个最任务,因此采用最小堆的数据结构
scheduler 为什么选择 message channel,而不是 requestIdleCallback,微任务,requestAnimationFrame,setTimeout
MessageChannel 接口本身是用来做消息通信的,允许我们创建一个消息通道,通过它的两个 MessagePort 来进行信息的发送和接收。 我们有说过 scheduler 是用来调度任务,调度任务需要满足两个条件:
- JS 暂停,将主线程还给浏览器,让浏览器能够有序的重新渲染页面
- 暂停了的 JS(说明还没有执行完),需要再下一次接着来执行
那么这里自然而然就会想到事件循环,我们可以将没有执行完的 JS 放入到任务队列,下一次事件循环的时候再取出来执行。
那么,如何将没有执行完的任务放入到任务队列中呢?
那么这里就需要产生一个任务(宏任务),这里就可以使用 MessageChannel,因为 MessageChannel 能够产生宏任务。
为什么没有选择 requestIdleCallback
- 兼容性问题,一个是不是所有浏览器都支持,caniuse 79%,另一个是 React 是一个跨平台,跨浏览器的解决方案,不能依赖于特定 API
- 无法保证优先级
- 无法保证任务的执行时间
为什么不选择 setTimeout
以前要创建一个宏任务,可以采用 setTimeout(fn, 0) 这种方式,但是 react 团队没有采用这种方式。
这是因为 setTimeout 在嵌套层级超过 5 层,timeout(延时)如果小于 4ms,那么则会设置为 4ms。而 scheduler 的时间切片是 5ms
为什么没有选择 requestAnimationFrame
这个也不合适,因为这个只能在重新渲染之前,才能够执行一次,而如果我们包装成一个任务,放入到任务队列中,那么只要没到重新渲染的时间,就可以一直从任务队列里面获取任务来执行。
而且 requestAnimationFrame 还会有一定的兼容性问题,safari 和 edge 浏览器是将 requestAnimationFrame 放到渲染之后执行的,chrome 和 firefox 是将 requestAnimationFrame 放到渲染之前执行的,所以这里存在不同的浏览器有不同的执行顺序的问题。
根据标准,应该是放在渲染之前。
为什么没有选择包装成一个微任务?
这是因为和微任务的执行机制有关系,微任务队列会在清空整个队列之后才会结束。那么微任务会在页面更新前一直执行,直到队列被清空,达不到将主线程还给浏览器的目的
react 时间切片是什么?
可以简单理解为一个时间段。
现在广泛使用的屏幕的刷新率一般是 60Hz,而在两次硬件刷新之间浏览器进行两次重绘是没有意义的,只会消耗性能。因此浏览器会利用这个时间间隔 1000ms/60 适当的对绘制进行节流,因此 16ms 就成为渲染页面的一个关键时间。
React 中使用的是 5ms,并没有使用传统的 16ms,也就是说没有实现帧对齐,因为大部分任务不需要与帧对齐,如果需要的话,可以使用 requestAnimationFrame。
调度器周期性的执行任务,防止主线程上还有其他高优先级任务,如用户交互事件。默认情况下,每帧内周期性执行几次
React 中哪些地方用到了位运算?
位运算可以很方便的表达“增、删、改、查”。在 React 内部,像 flags、状态、优先级等操作都大量使用到了位运算。
- 增:使用或运算即可。
- 删:使用异或
- 判断是否有某一个权限:使用与来进行判断
在 react 中:
- 用来标记 fiber 操作的 flags,使用的就是二进制;针对一个 fiber 的操作,可能有增加、删除、修改,但是我不直接进行操作,而是给这个 fiber 打上一个 flag,接下来在后面的流程中针对有 flag 的 fiber 统一进行操作。通过位运算,就可以很好的解决一个 fiber 有多个 flag 标记的问题,方便合并多个状态
- lane 模型:优先级机制,相比 Scheduler,lane 模型能够对任务进行更细粒度的控制,
- 上下文
是否了解过 React 中的 lane 模型?为什么要从之前的 expirationTime 模型转换为 lane 模型?
在 React 中有一套独立的粒度更细的优先级算法,这就是 lane 模型。
这是一个基于位运算的算法,每一个 lane 是一个 32 bit Integer,不同的优先级对应了不同的 lane,越低的位代表越高的优先级。
早期的 React 并没有使用 lane 模型,而是采用的的基于 expirationTime 模型的算法,但是这种算法耦合了“优先级”和“批”这两个概念,限制了模型的表达能力。优先级算法的本质是“为 update 排序”,但 expirationTime 模型在完成排序的同时还默认的划定了“批”。
使用 lane 模型就不存在这个问题,因为是基于位运算,所以在批的划分上会更加的灵活。
lane <=> EventPriority <=> Scheduler 优先级
Reconciler
render 的第二阶段
递归
- 递:beginWork 根据传入的 FiberNode,创建下一级 FiberNode
- 归:completeWork
Diff 算法是怎么样的
diff 计算发生在更新阶段,当第一次渲染完成后,就会产生 Fiber 树,再次渲染的时候(更新),就会拿新的 JSX 对象(vdom)和旧的 FiberNode 节点进行一个对比,再决定如何来产生新的 FiberNode,它的目标是尽可能的复用已有的 Fiber 节点。这个就是 diff 算法。
在 React 中整个 diff 分为单节点 diff 和多节点 diff。
所谓单节点是指新的节点为单一节点,但是旧节点的数量是不一定的。
单节点 diff 是否能够复用遵循如下的顺序:
判断 key 是否相同
如果更新前后均未设置 key,则 key 均为 null,也属于相同的情况
如果 key 相同,进入步骤二
如果 key 不同,则无需判断 type,结果为不能复用(有兄弟节点还会去遍历兄弟节点)
如果 key 相同,再判断 type 是否相同
- 如果 type 相同,那么就复用
- 如果 type 不同,则无法复用(并且兄弟节点也一并标记为删除)
多节点 diff 会分为两轮遍历:
第一轮遍历会从前往后进行遍历,存在以下三种情况:
- 如果新旧子节点的 key 和 type 都相同,说明可以复用
- 如果新旧子节点的 key 相同,但是 type 不相同,这个时候就会根据 ReactElement 来生成一个全新的 fiber,旧的 fiber 被放入到 deletions 数组里面,回头统一删除。但是注意,此时遍历并不会终止
- 如果新旧子节点的 key 和 type 都不相同,结束遍历
如果第一轮遍历被提前终止了,那么意味着还有新的 JSX 元素或者旧的 FiberNode 没有被遍历,因此会采用第二轮遍历去处理。
第二轮遍历会遇到三种情况:
只剩下旧子节点:将旧的子节点添加到 deletions 数组里面直接删除掉(删除的情况)
只剩下新的 JSX 元素:根据 ReactElement 元素来创建 FiberNode 节点(新增的情况)
新旧子节点都有剩余:会将剩余的 FiberNode 节点放入一个 map 里面,遍历剩余的新的 JSX 元素,然后从 map 中去寻找能够复用的 FiberNode 节点,如果能够找到,就拿来复用。(移动的情况)
如果不能找到,就新增呗。然后如果剩余的 JSX 元素都遍历完了,map 结构中还有剩余的 Fiber 节点,就将这些 Fiber 节点添加到 deletions 数组里面,之后统一做删除操作
整个 diff 算法最最核心的就是两个字“复用”。
React 不使用双端 diff 的原因:
由于双端 diff 需要向前查找节点,但每个 FiberNode 节点上都没有反向指针,即前一个 FiberNode 通过 sibling 属性指向后一个 FiberNode,只能从前往后遍历,而不能反过来,因此该算法无法通过双端搜索来进行优化。
React 想看下现在用这种方式能走多远,如果这种方式不理想,以后再考虑实现双端 diff。React 认为对于链表反转和需要进行双端搜索的场景是少见的,所以在这一版的实现中,先不对 bad case 做额外的优化。
对比 React18 与 Vue3-VDOM-DIFF?
- 子节点数据结构上:react 的 old 是单链表,vue 的 old 是数组,因此 React 只能单向查找,vue 双向查找
- 哈希表:为了快速通过 key 值找到节点,双方都用到了 map,React 根据 old 做出 map(value 是节点),vue 则是根据 new 做出 map(value 是 index, 因为可以根据 数组 [index] 找到节点);
- 如果 old 和 new 其中一方已经遍历完毕,两者处理相同,这也是必然的。
- vue 用到了 LIS(最长递增子序列)
延申:为什么 map 不是 object?
vdom diff 怎么确定节点的新增,删除,修改,怎么确定是要新增还是更新呢,如果没有 key 呢
React 的 VDOM diff 会通过 type 和 key 判断节点是否相同。如果 type 和 key 相同,就做属性和子节点更新;如果不同,就删除旧节点、新增新节点。
对于列表,带 key 时会用 key 做映射,精准定位新增、删除、移动;没有 key 时按顺序比较,容易误判修改,导致性能下降。建议列表场景一定加 key,推荐用稳定 ID,不用索引。
如果都没有设置 key,则认为都是 null,key 相同,则继续比较 type
JSX 是什么?
React 中用 jsx 来描述 view。 17 之前需要导入 React,否则会报错,因为 jsx 转换使用的是 React.createElement 17 之后,新的 jsx 自动从 React package 中引入新的入口函数并调用。
vdom 是什么,为什么要使用它?
vdom 最初是由 React 团队所提出的概念,这是一种编程的思想,指的是针对真实 UI DOM 的一种描述能力。 在 React 中,使用了 JS 对象来描述真实的 DOM 结构。vdom 和 JS 对象之间的关系:前者是一种思想,后者是这种思想的具体实现。 使用 vdom 有如下的优点:
- 相较于 DOM 的体积和速度优势
- JS 层面的计算的速度,要比 DOM 层面的计算快得多,且 DOM 上面的属性也是非常多的
- vdom 发挥优势的时机主要体现在更新的时候,相比较 innerHTML 要将已有的 DOM 节点全部销毁,vdom 能够做到针对 DOM 节点做最小程度的修改
- 多平台渲染的抽象能力
- 浏览器、Node.js 宿主环境使用 ReactDOM 包
- Native 宿主环境使用 ReactNative 包
- Canvas、SVG 或者 VML(IE8)宿主环境使用 ReactArt 包
- ReactTest 包用于渲染出 JS 对象,可以很方便地测试“不隶属于任何宿主环境的通用功能”
在 React 中,通过 JSX 来描述 UI,JSX 仅仅是一个语法糖,会被 Babel 编译为 createElement 方法的调用。该方法调用之后会返回一个 JS 对象,该对象就是 vdom 对象,官方更倾向于称之为一个 React 元素。
在循环渲染多个组件的时候,key 如何取值?
因为在协调阶段,组件复用的前提是同时满足三个条件,同一层级,同一类型,同一 key;
key 决定节点在当前层级下的唯一性,因此尽量不要取值 index,因为多个循环下 index 容易重复,并且如果涉及节点的增加删除移动,key 的稳定性会被破坏,节点就会出现混乱
介绍一下 Fiber 新架构
React v15 及其之前的架构:
- Reconciler(协调器):VDOM 的实现,负责根据自变量变化计算出 UI 变化
- Renderer(渲染器):负责将 UI 变化渲染到宿主环境中
这种架构称之为 Stack 架构,在 Reconciler 中,mount 的组件会调用 mountComponent,update 的组件会调用 updateComponent,这两个方法都会递归更新子组件,更新流程一旦开始,中途无法中断。
但是随着应用规模的逐渐增大,之前的架构模式无法再满足“快速响应”这一需求,主要受限于如下两个方面:
- CPU 瓶颈:由于 VDOM 在进行差异比较时,采用的是递归的方式,JS 计算会消耗大量的时间,从而导致动画、还有一些需要实时更新的内容产生视觉上的卡顿。
- I/O 瓶颈:由于各种基于“自变量”变化而产生的更新任务没有优先级的概念,因此在某些更新任务(例如文本框的输入)有稍微的延迟,对于用户来讲也是非常敏感的,会让用户产生卡顿的感觉。
新的架构称之为 Fiber 架构:
- Scheduler(调度器):调度任务的优先级,高优先级任务会优先进入到 Reconciler
- Reconciler(协调器):VDOM 的实现,负责根据自变量变化计算出 UI 变化
- Renderer(渲染器):负责将 UI 变化渲染到宿主环境中
首先引入了 Fiber 的概念,通过一个对象来描述一个 DOM 节点,但是和之前方案不同的地方在于,每个 Fiber 对象之间通过链表的方式来进行串联。通过 child 来指向子元素,通过 sibling 指向兄弟元素,通过 return 来指向父元素。
在新架构中,Reconciler 中的更新流程从递归变为了“可中断的循环过程”。每次循环都会调用 shouldYield 判断当前的 TimeSlice 是否有剩余时间,没有剩余时间则暂停更新流程,将主线程还给渲染流水线,等待下一个宏任务再继续执行。这样就解决了 CPU 的瓶颈问题。 另外在新架构中还引入了 Scheduler 调度器,用来调度任务的优先级,从而解决了 I/O 的瓶颈问题。
Fiber 是什么?
Fiber 可以从三个方面去理解:
- FiberNode 作为一种架构:在 React v15 以及之前的版本中,Reconceiler 采用的是递归的方式,因此被称之为 Stack Reconciler,到了 React v16 版本之后,引入了 Fiber,Reconceiler 也从 Stack Reconciler 变为了 Fiber Reconceiler,各个 FiberNode 之间通过链表的形式串联了起来。
- FiberNode 作为一种数据类型:Fiber 本质上也是一个对象,是之前虚拟 DOM 对象(React 元素,createElement 的返回值)的一种升级版本,每个 Fiber 对象里面会包含 React 元素的类型,周围链接的 FiberNode,DOM 相关信息。
- FiberNode 作为动态的工作单元:在每个 FiberNode 中,保存了“本次更新中该 React 元素变化的数据、要执行的工作(增、删、改、更新 Ref、副作用等)”等信息。
return chile sibling
为什么指向父 FiberNode 的字段叫做 return 而非 parent? 因为作为一个动态的工作单元,return 指代的是 FiberNode 执行完 completeWork 后返回的下一个 FiberNode,这里会有一个返回的动作,因此通过 return 来指代父 FiberNode
Fiber 双缓冲是什么
指的是在内存中构建两颗树,并直接在内存中进行替换的技术。在 React 中使用 Wip Fiber Tree 和 Current Fiber Tree 这两颗树来实现更新的逻辑。Wip Fiber Tree 在内存中完成更新,而 Current Fiber Tree 是最终要渲染的树,可以简单理解为真实 UI 对应的 Fiber Tree,两颗树通过 alternate 指针相互指向,这样在下一次渲染的时候,直接复用 Wip Fiber Tree 作为下一次的渲染树,而上一次的渲染树又作为新的 Wip Fiber Tree,这样可以加快 DOM 节点的替换与更新。
为什么要引入 Hooks,Hooks 解决了什么样的问题?
React 出现最初,99% 多少类组件,因为可以在类组件内部使用状态,使用副作用等。而这些在函数组件内部都做不到,因此以前的函数组件基本只能作为静态组件展示。
但类组件中有以下缺点:
- 组件之间复用状态逻辑很难:React 没有提供将可复用性行为附加到组件的途径,例如把组件连接到 store,因此我们只能使用 render props 或者高阶组件,而这很容易形成嵌套地狱
- 复杂组件变得难以理解:组件每个生命周期函数只能写一次,复杂组件的某个生命周期函数可能会存在多个不相关但是不得不组合在一起的代码。
- 难以理解:找不到 this
Hooks (React16.8 )的引入,使得在函数组件内部可以定义状态,可以使用副作用,可以自定义 hook 复用状态逻辑,也可以定义多个副作用,完美解决类组件臃肿的问题;
具体可参考 AntD3Form(HOC)到 AntD4/5Form 的演进;
什么是自定义 Hook?
useXyz,可以在里面使用 hooks api;推荐 ahooks
为什么 Hook 出现之后,函数组件中可以定义 state,保存在了哪里?
hook 出现之前,函数组件内部无法定义 state,主要是因为函数组件每次更新,定义在函数体的值都要重新初始化,没法保存。 而 hooks 提供的 useState 或者 useReducer 可以用函数组件在组件内定义 state,每一个 hook 都有对应的 hook 对象,这个对象上会存储状态值,这个 hook 对象又以单链表的数据结构存在 fiber 上,而 fiber 是 React 的 vdom,存在于内存中。
useState 与 useReducer 区别以及原理?
都是用于函数组件内部定义状态,状态更新,组件更新。 状态值存储在函数组件的 fiber.memoizedState 上。
useReducer 可以接受一个 reducer 函数,意味着可以把状态修改逻辑放在 reducer 函数中,还可以多次复用;
不同点是,useState 如果 setState 的时候, 新旧 state 一样,组件就不会更新;useReducer 如果 dispatch ,新旧一样也会更新;
组件初次渲染阶段:
- 把 state 存储到 hook.memoizedState
- 初始化更新队列,存储到 hook.queue 上
- 定义 dispatch 事件,并存储到 hook.queue 上。(注意现在 useState/useReducer 的 dispatch 事件不相同)
- 返回 [hook.memoizedState, dispatch]
组件更新阶段(批量更新)
- 检查是否有上次未处理的更新,如果有,则添加到更新队列(环形链表)上
- 循环遍历更新队列,得到 newState
- 把最终得到的 newState 复制到 hook.memoizedState 上从一个视图过渡到另一个视图
- 返回 [hook.memoizedState, dispatch]
执行 useReducer 的 dispatch 事件:dispatchReducerAction 创建一个 update 对象,存储到更新队列中,然后执行 scheduleUpdateOnFiber 函数,去更新
执行 useState 的 dispatch 事件:dispatchSetState 创建一个 update 对象,如果新的 state 和老的 state 相同,则退出更新,进入 bailout。否则存储 update 到更新队列中,然后执行 scheduleUpdateOnFiber 函数,去更新。
setState 批量更新的过程
18 之前,只有在 react 控制的上下文中触发批量更新,比如 react 生命周期函数,react 合成事件,useEffect/useLayoutEffect,如果存在异步代码比如 setTimeout, react 无法感知上下文,会立即执行。
18 之后自动批量更新拓展到了所有上下文,包括异步代码。
核心:将多个 setState 调用合并为一次更新,减少渲染次数。
执行流程:
- setState 被调用后,React 会将更新任务存入组件对应的更新队列中,而不是立即执行
- 检查 isBatchingUpdate
- true 将更新任务暂存到队列中,等待批量更新
- false 立即执行
- 生命周期或者合成事件结束后,react 会调用 flushSync 开始处理更新队列
- react 依次取出更新队列的任务,并将所有的 setState 合并为一个新的 state,规则是用 object.assign, 即后面的 setState 会覆盖前面的
- 触发渲染,更新视图
setState 是同步还是异步?
在 React 中 setState 并不会立刻同步更新,而是被加入批量更新队列,等到 React 完成当前事件循环后统一更新。这么做的好处是可以减少多次渲染,提升性能。从 React 18 开始,批处理行为不仅局限在 React 事件中,也支持了像 setTimeout、Promise.then 等异步回调内。也就是说,在这些场景下的 setState 也会被自动批处理,从而表现出“异步”的行为。如果确实需要立即同步更新,可以使用 ReactDOM.flushSync() 来强制同步更新。但通常不推荐频繁使用,除非特殊场景,比如表单状态的实时反馈。
如何理解 React 中的 state(状态)与 props(属性)?
React UI = fn(state); state 是变量,一般情况下,state 更新,组件会更新; props 是属性,用于父子通信,且不可修改; 但如果更新被拦截,比如使用了 shouldComponentUpdate 或者 PureComponent 或者 memo,更新会被按需拦截;
在函数/类组件中如何使用 state?
组件内部 state,适合只在本组件内部使用 state,优点是灵活,随时定义可用,缺点是难以实现组件间共享。 函数组件内部 state 可以使用
useState,useReducer定义; 类组件内部可以使用this.state定义,使用this.setState更改 state组件外部 state,也就是所谓的状态管理库,目前用的比较多的是 Redux,MobX,DVA/umi(基于 redux 封装的),AntD4 Form 也是自己在外部定义的状态管理;
为什么 useState/useReducer 返回一个数组,而不是其它结构,比如对象?
可以用户自定义命名
useRef 是干什么的?ref 的工作流程是怎样的?什么叫做 ref 的失控?
useRef 的主要作用就是用来创建 ref 保存对 DOM 元素的引用。 当开发者调用 useRef 来创建 ref 时,在 mount 阶段,会创建一个 hook 对象,该 hook 对象的 memoizedState 存储的是 { current: initialValue } 对象,之后向外部返回了这个对象。在 update 阶段就是从 hook 对象的 memoizedState 拿到 { current: initialValue } 对象。
ref 内部的工作流程整体上可以分为两个阶段:
- render 阶段:标记 Ref flag,对应的内部函数为 markRef
- commit 阶段:根据 Ref flag,执行 ref 相关的操作,对应的相关函数有 commitDetachRef、commitAttachRef
所谓 ref 的失控,本质是由于开发者通过 ref 操作了 DOM,而这一行为本身是应该由 React 来进行接管的,所以两者之间发生了冲突导致的。
useEffect/useLayoutEffect 用法与区别?
因为在函数主体内改变 DOM,添加订阅,设置定时以及执行其他包含副作用都是不被允许的,因为这可能会产生莫名其妙的 bug 并破坏 UI 的一致性。
共同点是函数签名一模一样,第一个参数接收一个函数 effect,第二个参数接受一个依赖数组。返回一个 destroy,如果 destroy 的函数,则会在组件更新或者卸载前执行。比如清除订阅,定时器等
- useEffect:回调函数会在 commit 阶段完成后异步(异步)执行,所以不会阻塞视图渲染
- useLayoutEffect:回调函数会在 commit 阶段的 Layout 子阶段同步执行,一般用于执行 DOM 相关的操作
每一个 effect 会与当前 FC 其他的 effect 形成环状链表,连接方式为单向环状链表。
其中 useEffect 工作流程可以分为:
- 声明阶段
- 调度阶段
- 执行阶段
useLayoutEffect 的工作流程可以分为:
- 声明阶段
- 执行阶段 之所以 useEffect 会比 useLayoutEffect 多一个阶段,就是因为 useEffect 的回调函数会在 commit 阶段完成后异步执行,因此需要经历调度阶段。
useEffect/useLayoutEffect 中的延迟、同步是什么意思?
这里所谓的延迟,同步,指的是 React 任务调度中的任务调度,所谓延迟就是 useEffect 的 effect 不与组件渲染使用同一个任务调度函数,而是再单独调用一次任务调度函数,即用的不是一个 task,因为如果 effect 和组件渲染用的同一个 task,那么 effect 势必会加长这个 task 的执行时间,阻碍组件渲染。 同理,useLayoutEffect 所谓同步,指的是 useLayoutEffect 的 effect 和组件渲染使用的是同一个 task,那么就会阻碍组件渲染。
因此大多数情况下,尽可能使用标准的 useEffect 以避免阻塞视觉更新。
在源码的 ReactFiberWorkLoop.js 的 commitRoot 函数中,useLayoutEffect 调用了 flushLayoutEffects,该函数里直接 commitLayoutEffects 了;而如果是 useEffect 的话,则会用 进入 scheduleCallback 里执行 flushPassiveEffects
AntD4/5 Form 的底层就是 form,也就是 rc-field-form 中的 field 如果用函数组件实现,就得使用 useLayoutEffect,如果使用 useEffect,就会发现组件没有初始值,这是因为 useEffect 的时候订阅会延迟,那么组件接收到 store 变更,却没有执行组件更新的操作,因为这个时候订阅没有发生;
react-router6 也是使用 useLayoutEffect 来监听;
为什么不能在循环,条件或嵌套函数中调用 Hook?
Hooks 使用规则:不能在条件,循环或者嵌套函数中调用 hook
React 中每个组件都有个对应的 FiberNode,其实就是一个对象,这个对象有个属性叫做 memoizedState。当组件是函数组件的时候,fiber.memoizedState 上存储的就是 Hooks 单链表。
单链表的每个 Hook 节点没有名字或者 key,因为除了他们的顺序,我们无法记录他们唯一性,因此为了确保每个 Hook 是它本身,我们不能破坏这个链表的唯一性。
解释下 useImperativeHandle 场景?
让用户可以把一个变量当作 ref 暴露出来,经常和 forwardRef 一起使用
- 把 ref 暴露给父组件,比如 antD4/5 中支持类组件实现。
- 暴露方法给父组件
封装了哪些 hooks
useUpdate?主要是强制更新,内部维护了一个 state,通过更新 state 去刷新页面 useLocalStorage? useCountdown
简述前端路由:前端路由解决的问题?
在前端开发中,我们可以使用路由设置访问路径,并根据路径与组件的映射关系切换组件的显示,而这整个过程都是在同一个 html 中实现的,不涉及页面间的跳转,这也就是我们常说的 SPA。
相比于 MPA,SPA 有以下优点:
- 不涉及 html 页面跳转,内容改变不需要重新加载页面,对服务器压力小。
- 只涉及组件之间的切换,跳转流畅,用户体验好
- 组件化开发边界
同时也有以下缺点:
- 首屏加载过慢
- 不利于 seo
- 页面复杂度提高很多
前端路由如何切换页面?
React-Router6 有三种路由模式,分别为 BrowserRouter,HashRouter,MemoryRouter。
React-Router 中 history、hash 路由差异?
HashRouter 最简单,因为服务端不解析 # 之后的字符,但是前端可以依据 hash 这个变化渲染组件。
BrowserRouter 就不同,使用 HTML5 history API,让页面的 UI 与 URL 同步。需要服务端配合,不然页面刷新会 404
react-router6 原理?
使用 Context 机制,从 Router 层传递 navigator,location,match 等参数给后代组件,同时 BrowserRouter,HashRouter 组件会监听 location,一旦 location 变化,即路由变化,那么就会执行 setState,导致组件更新,后代消费 navigator,location,match 等参数的组件也会更新
Context 使用方法?
使用场景:当祖先组件想要和后代组件快速通信,三步走
- 创建 context,可以设置默认值,如果缺少匹配的 Provider,那么后代组件将会读取这里的默认值
- Provider 传递 value 给后代组件
- 后代组件消费 value
- contextType: 只能在类组件上使用且只能订阅单一的 Context 来源
- useContext:函数组件或者自定义 hooks 中
- Consumer 组件,无限制
讲述 Context 原理?
单链表的结构存在 fiber 上。
记录了一个全局变量:
currentlyRenderingFiber:记录当前可以消费的 Provider value 的后代组件,valueCursor:栈,记录每一层 Provider value 值;lastContextDependency:记录最后一个 currentlyRenderingFiber 上的最后一个 context
- 能消费 Provider value 的后代组件类型只能是函数组件,类组件,consumer 组件,forwardRef 组件,因此在这些组件开始更新的时候,会执行一个 prepareToReadContext 函数,用于记录当前组件的 fiber,记录到一个叫做 currentlyRenderingFiber 全局值中
- 当执行到 provider 组件的更新函数时,执行 pushProvider 函数,用一股把 value 存在一个栈中,当这个 Provider 组件执行完毕,则把这个 value 出栈。
- Provider 组件更新完成之后,把 value 出栈
组件如何通信以及不同通信方式的特点?
- 父子组件:props, 缺点是不适合多层级的祖先与后代。
- 子父组件:函数返回值
- 兄弟组件:交给共同的父组件管理,比如 AntD3 Form,缺点是一个子组件更新,会导致父组件更新。
- 祖先/后代组件:Context。不适合大量使用,因为一旦 Context 发生改变,涉及所有组件都会更新,影响比较广,因此项目中应该谨慎使用。
- 远亲组件:即组件层级不确定,此时比较适合使用第三方组件状态管理库,如 Redux,MobX,Recoil 等,AntD4/5 Form 中也是这个用法。
什么是 HOC,如何”修改”组件属性 props?
HOC 是高阶组件,他是个函数,接收组件作为参数,返回一个新的组件(所以不叫作 props 被修改了),hooks 出现之前,常用于复用逻辑; 比如 react-redux 的 connect,router5 的 withRouter,AntD3 的 create,mobX 的 inject 等等; 但是现在用的不多了,原因是容易形成嵌套地狱;
在函数/类组件中如何使用 state?
组件内部 state,适合只在本组件内部使用 state,优点是灵活,随时定义可用,缺点是难以实现组件间共享。 函数组件内部 state 可以使用
useState,useReducer定义; 类组件内部可以使用this.state定义,使用this.setState更改 state组件外部 state,也就是所谓的状态管理库,目前用的比较多的是 Redux,MobX,DVA/umi(基于 redux 封装的),AntD4 Form 也是自己在外部定义的状态管理;
比较函数组件与类组件的内部状态?
相同点是都是用来定义组件状态,并且状态更新,组件也更新。 不同点有:
- API 不同:类组件 this.state/setState; 函数组件 useState, useReducer
- 存储方式不同:类组件的 state 存储在类组件实例和 fiber 上(这也是不可以使用 this.state.count = xxx 来更新 state 的原因, 这样的话只是更新了类组件实例, fiber 没更新);函数组件的 state 存储在 fiber 的 hook 上
- 更新不同:this.setState 的时候,类组件的新的 state 与旧的 state 合并对象(Object.asign), 组件都会进行更新(手动拦截除外);函数组件是新的 state 覆盖旧的 state,并且在 useState 的 setState 中,新旧 state 相同,则函数组件拒绝更新(bailout)
- 组件使用 state 的时候,取值来源不同:类组件中使用 state 直接使用 this.state, 他的值来自于类组件实例(fiber 与类组件实例上的 state 保持同步);函数组件中使用 state,直接使用 useState 或者 useReducer 函数返回数组的第 0 个元素,这个值来自于 fiber 上的 hook 对象。
换句话说,如果想要获取类组件的新的状态值,可以直接访问 this.state; 而如果想要获取函数组件中的一个新的状态值,必须重新执行 useState 或者 useReducer 函数,即必须执行函数组件;
类组件的 componentDidMount 与 useEffect/useLayout?
componentDidMount 执行时机同 useLayoutEffect,源码中体现在 commitLayoutEffectOnFiber 上。
switch (finishedWork.tag) {
case FunctionComponent:
case ForwardRef:
case SimpleMemoComponent: {
// ...
if (flags & Update) {
commitHookLayoutEffects(finishedWork, HookLayout | HookHasEffect); // useLayoutEffect
}
break;
}
case ClassComponent: {
// ...
if (flags & Update) {
commitClassLayoutLifecycles(finishedWork, current);
} // componentDidMount
// ...
break;
}
// ...
}引发的思考:涉及的更新的订阅应当写在 componentDidMount 或者 useLayoutEffect 中,比如用函数组件实现 AntD4/5 Form 的 field,(注意 rc-field-form 的 Field 使用的是类组件实现的,因此使用的是 componentDidMount 生命周期)如果要使用函数组件实现,则要使用 useLayoutEffect
类组件生命周期,以及废除三个老生命周期的原因?
废弃了三个 will_xxx;改为了 UNSAFE_componentWillMount/Update/ReceiveProps
从 16.3(引入 fiber 架构) 开始,这三个生命周期不再被推荐使用了,因为随着 React 架构的迭代,组件的更新事件将不再确定(异步渲染),并且可能会被打断中止,那么“将要挂载,更新,接收参数”都将变得不再可靠。
受控组件与非受控组件
在 React 中,**受控组件(Controlled Components)**指的是表单元素的值由 React 的 state 控制,**非受控组件(Uncontrolled Components)**则是由 DOM 自己管理其状态,通过 ref 访问。受控组件更符合 React 的理念(数据驱动 UI),推荐默认使用
eagerState 策略
eagerState 的核心逻辑是如果某个状态更新前后没有变化,则可以跳过后续的更新流程。该策略将状态的计算提前到了 schedule 阶段之前。当有 FiberNode 命中 eagerState 策略后,就不会再进入 schedule 阶段,直接使用上一次的状态。
该策略有一个前提条件,那就是当前的 FiberNode 不存在待执行的更新,因为如果不存在待执行的更新,当前的更新就是第一个更新,计算出来的 state 即便不能命中 eagerState,也能够在后面作为基础 state 来使用,这就是为什么 FC 所使用的 Update 数据中有 hasEagerState 以及 eagerState 字段的原因
bailout 策略
在 beginWork 中,会根据 wip FiberNode 生成对应的子 FiberNode,此时会有两次“是否命中 bailout 策略”的相关判断。
第一次判断
- oldProps 全等于 newProps
- Legacy Context 没有变化
- FiberNode.type 没有变化
- 当前 FiberNode 没有更新发生
当以上条件都满足时会命中 bailout 策略,之后会执行 bailoutOnAlreadyFinishedWork 方法,该方法会进一步判断能够优化到何种程度。
通过 wip.childLanes 可以快速排查“当前 FiberNode 的整颗子树中是否存在更新”,如果不存在,则可以跳过整个子树的 beginWork。这其实也是为什么 React 每次更新都要生成一棵完整的 Fibrt Tree 但是性能并不差的原因。
- 第二次判断:
- 开发者使用了性能优化 API,此时要求当前的 FiberNode 要同时满足:
- 不存在更新
- 经过比较(默认浅比较)后 props 未变化
- ref 不变
- 虽然有更新,但是 state 没有变化
- 开发者使用了性能优化 API,此时要求当前的 FiberNode 要同时满足:
组件的常见性能优化手段?
复用组件:前提必须同时满足同一层级,同一类型,同一个 key,所以我们要尽量保证这三者的稳定性
减少不必要的更新:组件更新会导致组件进入协调,协调的核心就是我们常说的 vdom diff,所以协调本身就是比较耗时的算法。因此如果能够减少协调,复用旧 fiber 节点,那么肯定会加快渲染完成的速度。组件如果没有进入协调阶段,我们称之为进入 bailout 阶段,意思就是退出更新。
让组件 bailout 阶段有以下方法:
- shouldComponentUpdate:类组件的生命周期之一,当用户定义这个函数并且返回 false,则进入 boilout;
- PureComponent:更新会自动进行 shallow compare 新旧 props 与 state,如果没变化,就进入 boilout;
- memo:第一个参数是组件,第二个参数是一个比较函数,默认为浅比较 props。
- useMeme 和 useCallback 缓存
React 事件机制?
我们在 React 中使用的 onClick,onChange 这种驼峰命名的事件,通常称之为合成事件。
React 自定义合成事件机制,帮助用户解决了平台兼容性,事件委托等优化机制,消除不同浏览器在事件处理上的差异性,用户只需要关注写 React 本身就行了。
关于合成事件,React17 曾发生过一次变化,17 以前,事件是委托在 document 上,但是实际上,React 项目是可以作为其他项目的子项目的,17 之后就把事件委托在了自己的 container 层 事件委托又称为事件代理机制,这种事件机制是指把所有子节点的事件都把规定在父级,使用一个统一的事件监听和处理函数。这样可以简化事件处理和回收机制,从而提升效率
React 版本之间的差异?
- 16.3 引入 fiber 架构,willXXX 生命周期被标记为 unsafe 了
- 16.8 引入 hooks
- 17 垫脚石版本 :
- jsx 转换
- 事件委托的变更
- 时间系统相关更改
- 去除事件池
- 返回一致的 undefined 错误
- 启发式更新算法更新
- 18 大量新特性出现,如自动批量处理,非紧急更新,concurrent 等
17 之后弃用了 event pooling?
event pool 就是 React 用来复用事件对象的。事件触发前,从池中取出事件对象,填充相关信息,事件处理完成后,将事件对象重置并放回事件池,以便下次复用。
因为对象池的机制,经常导致 React 中的 event 在下个事件循环中被释放的情况,比如异步的情况,不得不使用 persist 方法去阻止对象的释放回收,对象池给 React 用户带来了一些负担;
function handleClick(event) {
event.persist(); // 防止事件对象被重置
setTimeout(() => {
console.log(event.type); // 正常工作,但如果没添加 persist ,就会报错,因为事件对象被重置
}, 1000);
}设计的初衷是:在早期的 JavaScript 引擎中,频繁创建和销毁对象(如事件对象)会导致性能问题。但是现在引擎已经相当高效了
V8 在堆内存中开辟出新生代和老生代的划分区,分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,事件对象的生命周期通常较短(仅在事件处理期间有效);
其次,V8 使用增量垃圾回收(Incremental GC)和并发垃圾回收(Concurrent GC),可以在不阻塞主线程的情况下高效回收内存。 这意味着即使 React 每次事件触发都创建新的事件对象,V8 也能快速回收这些对象,不会对性能造成明显影响。
基于 V8 的上述两点主要优化可以看到,对于小的对象创建,实际上 GC 的压力已经不再是瓶颈了,将老生代剥离出去和多线程的机制,已经让 GC 是一个非常轻量的过程,而 JS 创建对象的数量始终是有限的,所以在目前看来,在大多数应用中,使用 JS 的对象池技术是没有太大必要的。
react19 新特性
- 新 hooks
14.resume
LCP 从 4.2s 优化至 1.5s 了
我自己的习惯是会定期的跑一下简单的性能测试,当时由于新项目为了赶进度,在开发初期其实没有很严格的做 code review,发现瓶颈主要集中在 NFT 预览图渲染、链上数据获取慢
首先 chrome 对 LCP 优化上的建议以及 vite 给到我们的建议,进行自查
基础优化:
- SPA 懒加载动态加载组件
- 首页 banner chakra Image 组件代替 img,自带一些 lazy load 等优化,并且由于 banner 是配置在后端的,在配置的时候要求做一些压缩和格式转换 尽量 webp,这是主要原因
- vite 分包:根据 bundle 分析结果具体分析,公告模块一般单独,这样也能合理利用缓存
- 使用预加载关键字体等
- 代码层面:减少无效渲染,使用 React.memo、useMemo、useCallback 避免不必要的重渲染。
- 替换重量库(lodash → lodash-es、moment → dayjs)
进一步优化:
- Skeleton + Content Hydration 优化,改善页面白屏感知,提升“心理性能”
- 使用 Service Worker 做首次加载缓存,缓存壳层,加快二次加载;首屏保持极小体积,后期我们也升级成 PWA 应用。
- CDN 缓存一些 CSS、字体、图片放到 CDN 上,提高资源加载速度
重计算逻辑封装至 Web Worker,实现主线程无阻塞计算
我们后端接口设计的原子化非常高,借贷的撮合逻辑就落到了前端;这其中涉及大量 抵押借贷业务的计算逻辑(如分期付款计划、利息拆分)等,这些逻辑计算复杂且依赖多轮循环、精度处理。
buyer 进入到商品页面,会获取所有满足条件的借贷池子,buyer 可以滑动 slider 选择借贷比例,天数等
业务逻辑拆分为纯函数模块:原本嵌套于组件内部的复杂计算,如贷款计划生成器、分期利息算法等,被提取为无副作用纯函数。
封装 Worker 通信协议,建立主线程与 worker 的异步通信通道。
借贷计算不写在后端吗
是的,核心的业务规则(比如分期计算公式、撮合逻辑)在服务端是一定要有的,确保安全性和一致性。
但我这里在前端封装一套重计算逻辑,主要目的是为了提升用户交互的实时性:当用户拖动滑块调整借款金额、期限或利率时,前端能立即预估分期计划、利息支出和还款节奏,实现「所见即所得」。如果这些都依赖后端接口,会有明显的请求延迟,体验会变差。
前端的计算结果只是用于展示,最终的撮合与风控判断还是由后端来做,结果也必须服务端二次确认,所以不会带来一致性或安全性问题。
webpack 150 - 30 ?
当时项目背景是,umi2 和 webpack4 版本;
首先我放弃了升级 umi3 和 webpack5 的方案,因为单比较 w5,配置上差异比较大,umi 也是同理;全覆盖测试是有必要的;
使用 speed-measure-webpack-plugin 来对耗时做一个分析,得出的结论是 js css 的一些 loader 话费了大量的时间,其次是代码压缩;因此提速的三个方向:
- 减少编译内容
- 榨干计算资源 — 多进程 w5:thread-loader 指定 worker 数;w4:happy-pack; 官方不推荐的状态
- 缓存编译内容 w5:cache;w4:cache-loader(官方:不推荐的状态
前两者的话综合项目背景的话,提速效益不高;
最后结论是 通过缓存编译内容来实现编译提速(空间换时间),缓存编译内容首先想到 dll;但配置繁杂,umi 也集成了这个插件,但是官方也对这个插件持消极态度;最终找了 hard-source-webpack-plugin 这个比较完美的替代方案;
hard-source-webpack-plugin:持久化缓存结果缓存至硬盘上,这个插件的原理大概是:第一次编译的是,采用文件的 hashcode 来标记结果,讲编译结果与 hashcode 关联起来。第二次编译文件的时候,首先加载本地缓存结果(这个过程非常快)。然后进入正常编译阶段,插件会将需要编译的文件再次计算 hashcode,如果某一个 code 已经存在,将直接跳过编译环节,直接输出编译结果,存到 node_modules 下的。cache 目录下,第二次构建的时候再取出缓存使用
随着项目的迭代,项目会越来越大,那么首屏加载的时候肯定会上去,怎么处理呢
- 路由懒加载 react.lazy()
- splitchunks
- SSR
- 资源优化
- tree shaking 比如 lodash-es
- terser 自定义压缩
- 图片优化 小图,压缩,或者 webp
- 字体 subset
- CDN:JS、CSS、字体、图片放到 CDN 上,提高资源加载速度。
- 缓存优化
项目中是否有做,首屏加载超过一个阈值,就告警之类的
我们对首页和核心业务页面做了 LCP 和白屏时间的性能监控。我们设置了性能阈值(例如 LCP 超过 3s),一旦异常占比超过 10%,就会通过 Webhook 触发飞书/钉钉告警。同时我们也会采集用户网络环境、设备类型等辅助信息,定位慢加载是否和 CDN、网络波动或某版本资源相关。整个方案通过 Performance API + sentry
首屏相关
首屏加载指标细化:
- FP(First Paint)首次绘制
- FCP(First Contentful Paint)首次内容绘制,FP 到 FCP 中间其实主要是 SPA 应用 js 执行时间,太慢的话就会白屏太长
- FMP(First Meaningful Paint)主要内容呈现的时间
- LCP(Largest Contentful Paint)最大内容渲染,提现加载最大内容的呈现时间
- TTI 可交互时间 ssr 的时候要重点考虑
SSR 是终极方案
白屏时间 vs 首屏时间
- 白屏时间 FCP
- 首屏时间 LCP
计算:PerformanceObserver
Lighthouse
lighthouse 有哪些指标?
2022 年谷歌推出 web 核心指标计划,没有必要搞很多指标来衡量性能,核心 web 指标计划旨在简化场景,统一网页性能衡量指标; core web vitals:
- LCP(largest contentful paint)2.5s 内,专注于加载性能 为什么不是 FCP(First contentful Paint):大部分页面都有 loading 态,loading 开始的时候 fcp 计算已结束,意义不大
- INP(Interaction to Next Paint)网页对用户输入的响应速度 200ms 内
- CLS(Cumulative Layout Shift)小于 0.1,专注于视觉稳定性
加载优化
目标:加载少,加载快
- 加载的资源无非就以下几大类(越小越好)
- 图片
- css 实现
- 压缩
- 使用 webp/avif 边缘计算
- 懒加载 loading:lazy
- 视频管理 gif,google 做过一个实验,4M 的 gif,mp4 只要 500K,webm 只要 300K
- 响应式
- 字体
- 使用 woff2 比 woff 小 30%
- 指定 unicode-range
- js
- 按需引入 UI 库
- tree shaking,比如使用 lodash-es 代替 lodash
- 路由懒加载
- 压缩代码
- 基于 canvas 加载?
- CSS
- purgecss 移除没用到的样式
- 压缩代码
- 懒加载非关键的 css 借助 criticalcss
- 图片
- 加载资源越快越好
- 最大限度的利用缓存
- 配置 cache-control,ETag
- 做好分包策略
- hash/chunkhash/contenthash
- pwa
- 优化加载速度
- 14kb 原则
- 使用 CDN
- 开启 http2/http3
- dns-prefetch/preload/prefetch/preconnect
- 最大限度的利用缓存
SEO 相关
技术上,我认为 SEO 优化可以分为结构优化、性能优化和可爬取性优化三大块:
结构优化:我会确保页面使用语义化标签,比如
, , ,并合理设置 、<meta> 描述、关键词,以及 H1-H6 层级,利于搜索引擎理解内容结构; 性能优化:加快首屏加载时间,提升 Core Web Vitals 指标(像 LCP、CLS),对 SEO 也有直接影响;
可爬取性优化:我参与过使用 Next.js 实现 SSR(服务端渲染),解决传统 SPA 页面内容被搜索引擎抓不到的问题。同时也配置了 sitemap.xml、robots.txt 让搜索引擎更好地发现与索引页面;
- sitemap 诉搜索引擎网站有哪些页面、更新频率、优先级等,帮助其更快抓取收录,一般通过插件自动生成
- robots.txt 告诉搜索引擎哪些页面允许抓取、哪些禁止抓取,防止泄露隐私页面或浪费爬虫预算,用来控制爬虫权限,比如限制访问后台或接口路径,同时声明 sitemap 地址,方便收录。
最后结合 fb 有个 seo 工具,进一步自查;
内部脚手架是怎么设计的?怎么提升团队效率?
我主导开发了一个前端脚手架工具,核心基于 Node.js + Inquirer + commander,支持快速生成我们公司几种业务版图,tg 小程序项目,普通的 nextjs 项目,官网项目等等
目的是去创建一个项目,其次去预置一些通用代码,比如内部的一些代码,比如一些埋点,http 请求封装,以及一些常用的工具函数,其次在构建和发布方面,还有 docker 的生成与上传,ci 的一些配置等等,保持风格和样式的统一;
代码风格是如何统一的:eslint、prettier、style-lint;
eslint:侧重语法的检验,prettier:侧重格式的统一
推动落地了 Puppeteer 的测试框架,是怎么做的?
我们当时需要一个能模拟用户真实操作的端到端测试方案,选型时调研了 Puppeteer、Cypress 和 Playwright:
最终选 Puppeteer,Puppeteer 配置更轻量,更符合当时的场景,
编写了基于页面路由的自动化登录 + 功能回归脚本脚本,后续就交给小组的其他同事负责
推动这个方案前后花了两周时间调研 + POC,落地后有效降低线上回归 Bug 20% 以上。
镜像体积太大?
- 尽量减少层级、构建基础镜像;
- 考虑从更换基础镜像源的方式
- 看看是否使用了过于臃肿的镜像源 因为 Alpine 镜像和类似的其他镜像都经过了优化,其中仅包含最少的必须的软件包;alpine 是轻型 Linux 发行版,提供了包管理工具 比如 nginx:最新版本 142mb,alpine 的只有 23.4MB node:14 846MB,alpine:172MB 编译好的文件复制进来即可
项目亮点
反作弊
- 接口层面
- 限制单用户请求频率
- 指纹
- 接口加密
接口加密
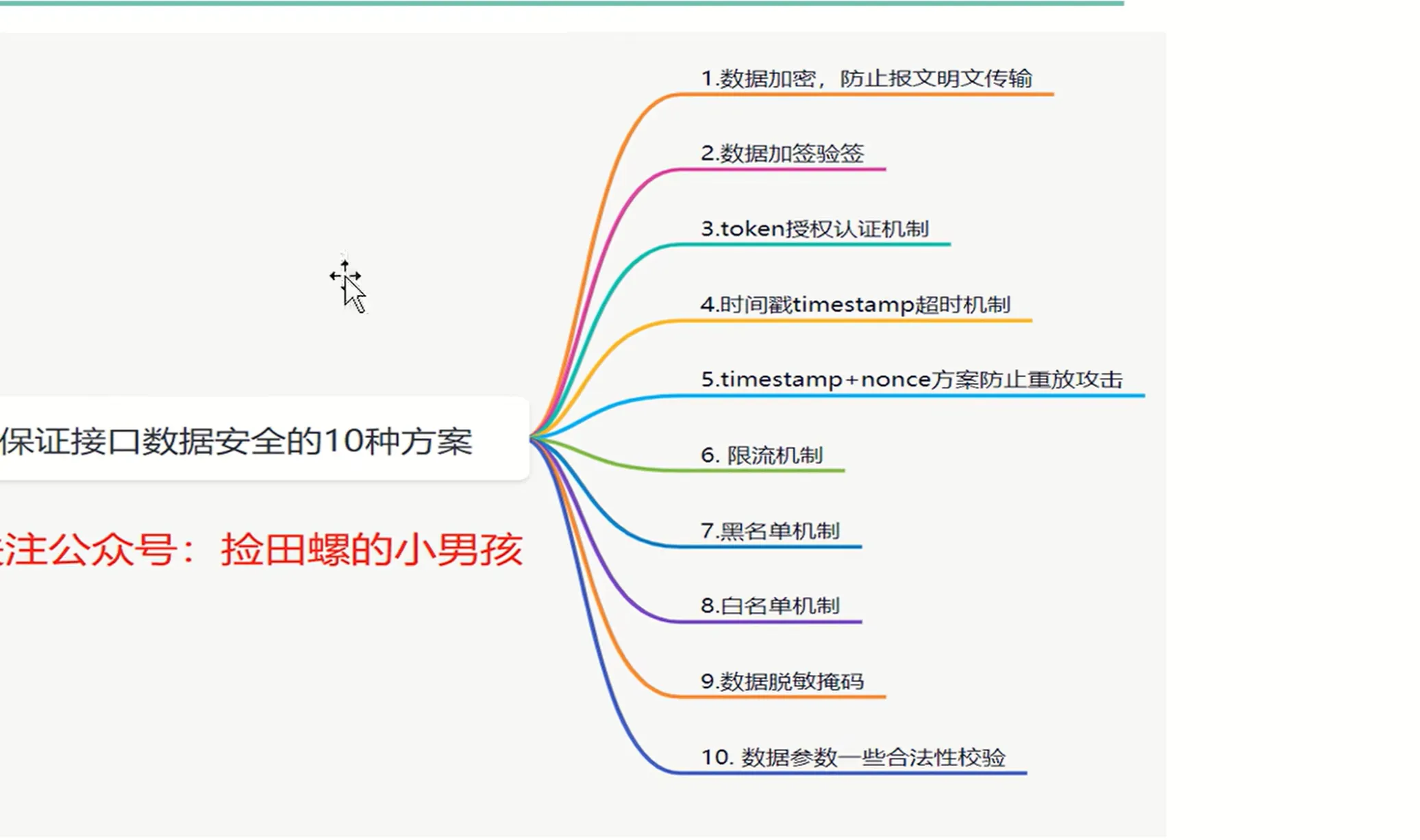
大文件上传和断点续传和显示进度条
核心:分片 + 并发 + 合并
将文件用 File.slice 方法分片(比如每片 1MB),生成每一片的唯一 hash 标识。然后用多线程并发上传每个 chunk。上传前我会向后端请求已上传的 chunk 列表,实现断点续传。上传过程中,我会监听 axios.onUploadProgress 实时更新进度条。最后所有分片上传完成后,请求后端合并文件。
鉴权
Wheel 自己实现
graphQL
水印
通过 document.createElement(‘canvas’);去绘制水印,相当于加一个蒙层去绘制水印,但这样有个缺陷就是我们做前端的会打开控制台,可以把水印给去掉,为了防止这个,采用 mutation observe 去监听 dom 是否有变化,如果有变化重新给他加上
微前端
webpack 联邦模块
小程序 Taro,是如何实现多端编译的
Taro 是京东·凹凸实验室开源的跨端框架,使用 React 语法编写,可以编译成微信小程序、H5、RN 等,一套代码,编译多端
Taro 会将使用 JSX 编写的组件代码经过 AST 分析 → 转换为对应平台的模板语言(如 wxml、html)。
hybrid app
PWA 离线缓存是怎么做的
PWA 的离线能力是通过注册 Service Worker,在安装阶段预缓存资源,在 fetch 阶段拦截请求优先从缓存返回,从而实现离线访问。
错误监控,搭建过程
一次导出 10 万条数据为 excel,页面卡顿,如何处理
- 后端导出
- web worker
- 分批
SSR CSR SSG ISR
SSR:
- 首屏加载快,SEO 友好
- 内容对搜索引擎和爬虫友好
- 对低性能设备更友好
但是:
- 服务端压力大,可能响应慢
- 首次渲染需要等待服务端完成
- 服务器复杂度较高
适用于:新闻站、博客、电商首页、SEO 要求高的页面
CSR:
- 交互丰富,体验流畅
- 减轻服务器压力
- 前后端分离灵活
但是
- 首屏加载慢,白屏时间长
- SEO 较差
- 依赖 JS,关闭 JS 时页面无内容
适用于:SPA 应用、后台管理系统、用户操作频繁页面
SSG:
- 访问速度极快
- 无需服务器渲染压力
- SEO 友好
- 部署简单
但是
- 生成时长长,构建时间随内容量增加
- 内容不实时,更新需要重新构建
适用于:文档网站、博客、产品官网、内容变化不频繁站点
ISR:
- 结合了 SSG 的速度和 SSR 的实时性
- 页面按需静态生成和更新
- 服务器负载均衡
但是
- 实现复杂,需要缓存和增量更新机制
- 可能存在短暂的内容过期窗口
适用于:大型内容站点、电商平台(首页+部分商品页)
白屏的可能出现的时间点
页面白屏的可能原因包括:
- 网络请求失败(DNS、服务器),
- 关键资源(HTML、CSS、JS)加载失败,
- JS 执行报错阻塞渲染,异步数据未加载导致无内容渲染,
- 路由配置错误导致组件未渲染。
排查时可以从 Network、Console、Elements 面板逐步定位,关键是保证关键资源加载无误和 JS 逻辑正确执行。
h5 竖屏切换到横屏要做什么处理
H5 页面从竖屏转为横屏时,主要需要监听 resize 或 orientationchange 事件,实时获取屏幕尺寸和方向,动态调整页面布局和样式。通常结合 rem 适配和媒体查询处理不同方向的样式差异。针对横屏可能出现的视口单位异常、布局错乱等问题,需要做兼容处理。对于某些业务场景,还会给用户做方向切换提示,确保体验一致。
js 的堆栈和 v8 的堆栈
在 JavaScript 语言层面,堆和栈是内存管理的抽象概念,基本类型存储在栈中,引用类型存储在堆中。栈用于管理函数调用的执行上下文,访问快且自动管理;堆用于存储对象,大小动态且需要垃圾回收。而 V8 引擎是 JS 的具体实现,它维护了调用栈来跟踪函数调用,并实现了堆内存的分配和高效垃圾回收机制。V8 还做了优化如分代回收、新生代老生代区分等,提高性能。简单来说,JS 堆栈是语言模型,V8 堆栈是具体引擎实现,两者层级不同。
一个 url 打开很慢,要怎么定位问题
“慢”可以是后端问题、前端资源问题、网络问题或渲染问题,我会按以下步骤分析”
步骤 1:先确认是“所有人都慢”还是“部分人慢”
- 所有人慢:服务器、后端、部署问题
- 地域慢、偶现:网络、CDN、DNS 问题
- 工具:
- 日志系统(采样用户耗时)
- CDN 日志、测速平台、监控系统(如阿里云 ARMS)
步骤 2:看 DNS、TCP、TTFB 耗时,在 Network 面板中分析
- DNS Lookup:慢 → 换 DNS、使用缓存
- SSL Handshake:慢 → HTTPS 证书部署问题
- TTFB(首字节时间):慢 → 后端接口慢、数据库慢
步骤 3:资源加载问题
- JS/CSS 文件过大未分包(看 Network)
- 图片体积过大(未压缩、未懒加载)
- 请求数量多(未合并、重复请求) 解决方案:
- Webpack 分包(Code Splitting)
- 图片压缩 + 懒加载
- HTTP/2 并发
步骤 4:主线程阻塞或 JS 太大:Performance 面板查看:
- 紫色大块 JS → JS 包太大
- Layout/Reflow 频繁 → 页面结构复杂 解决方案:
- 异步加载 JS(defer、lazy)
- 动画节流、DOM 简化、CSS 复杂度降低
步骤 5:首屏优化问题
- 是否开启 SSR(服务端渲染)
- 是否启用骨架屏 / loading 占位
- 是否懒加载首屏外资源
我会先用浏览器 DevTools 的 Network 面板排查是否是 DNS、SSL、接口响应慢的问题。再通过 Performance 分析主线程是否阻塞,比如 JavaScript 执行是否太重。之后我会看资源加载是否太多或太大,是否有图片未压缩或请求未懒加载。最后看是否首屏渲染策略不当,比如没有 SSR、异步数据加载阻塞渲染等。必要时结合后端日志和接口响应时间进一步定位瓶颈。