14.项目
LCP 从 4.2s 优化至 1.5s 了
我自己的习惯是会定期的跑一下简单的性能测试,当时由于新项目为了赶进度,在开发初期其实没有很严格的做 code review,发现瓶颈主要集中在 NFT 预览图渲染、链上数据获取慢
首先 chrome 对 LCP 优化上的建议以及 vite 给到我们的建议,进行自查
基础优化:
- SPA 懒加载动态加载组件
- 首页 banner chakra Image 组件代替 img,自带一些 lazy load 等优化,并且由于 banner 是配置在后端的,在配置的时候要求做一些压缩和格式转换 尽量 webp,这是主要原因
- vite 分包:根据 bundle 分析结果具体分析,公告模块一般单独,这样也能合理利用缓存
- 使用预加载关键字体等
- 代码层面:减少无效渲染,使用 React.memo、useMemo、useCallback 避免不必要的重渲染。
- 替换重量库(lodash → lodash-es、moment → dayjs)
进一步优化:
- Skeleton + Content Hydration 优化,改善页面白屏感知,提升“心理性能”
- 使用 Service Worker 做首次加载缓存,缓存壳层,加快二次加载;首屏保持极小体积,后期我们也升级成 PWA 应用。
- CDN 缓存一些 CSS、字体、图片放到 CDN 上,提高资源加载速度
重计算逻辑封装至 Web Worker,实现主线程无阻塞计算
我们后端接口设计的原子化非常高,借贷的撮合逻辑就落到了前端;这其中涉及大量 抵押借贷业务的计算逻辑(如分期付款计划、利息拆分)等,这些逻辑计算复杂且依赖多轮循环、精度处理。
buyer 进入到商品页面,会获取所有满足条件的借贷池子,buyer 可以滑动 slider 选择借贷比例,天数等
业务逻辑拆分为纯函数模块:原本嵌套于组件内部的复杂计算,如贷款计划生成器、分期利息算法等,被提取为无副作用纯函数。
封装 Worker 通信协议,建立主线程与 worker 的异步通信通道。
借贷计算不写在后端吗
是的,核心的业务规则(比如分期计算公式、撮合逻辑)在服务端是一定要有的,确保安全性和一致性。
但我这里在前端封装一套重计算逻辑,主要目的是为了提升用户交互的实时性:当用户拖动滑块调整借款金额、期限或利率时,前端能立即预估分期计划、利息支出和还款节奏,实现「所见即所得」。如果这些都依赖后端接口,会有明显的请求延迟,体验会变差。
前端的计算结果只是用于展示,最终的撮合与风控判断还是由后端来做,结果也必须服务端二次确认,所以不会带来一致性或安全性问题。
webpack 150 - 30 ?
当时项目背景是,umi2 和 webpack4 版本;
首先我放弃了升级 umi3 和 webpack5 的方案,因为单比较 w5,配置上差异比较大,umi 也是同理;全覆盖测试是有必要的;
使用 speed-measure-webpack-plugin 来对耗时做一个分析,得出的结论是 js css 的一些 loader 话费了大量的时间,其次是代码压缩;因此提速的三个方向:
- 减少编译内容
- 榨干计算资源 — 多进程 w5:thread-loader 指定 worker 数;w4:happy-pack; 官方不推荐的状态
- 缓存编译内容 w5:cache;w4:cache-loader(官方:不推荐的状态
前两者的话综合项目背景的话,提速效益不高;
最后结论是 通过缓存编译内容来实现编译提速(空间换时间),缓存编译内容首先想到 dll;但配置繁杂,umi 也集成了这个插件,但是官方也对这个插件持消极态度;最终找了 hard-source-webpack-plugin 这个比较完美的替代方案;
hard-source-webpack-plugin:持久化缓存结果缓存至硬盘上,这个插件的原理大概是:第一次编译的是,采用文件的 hashcode 来标记结果,讲编译结果与 hashcode 关联起来。第二次编译文件的时候,首先加载本地缓存结果(这个过程非常快)。然后进入正常编译阶段,插件会将需要编译的文件再次计算 hashcode,如果某一个 code 已经存在,将直接跳过编译环节,直接输出编译结果,存到 node_modules 下的。cache 目录下,第二次构建的时候再取出缓存使用
随着项目的迭代,项目会越来越大,那么首屏加载的时候肯定会上去,怎么处理呢
- 路由懒加载 react.lazy()
- splitchunks
- SSR
- 资源优化
- tree shaking 比如 lodash-es
- terser 自定义压缩
- 图片优化 小图,压缩,或者 webp
- 字体 subset
- CDN:JS、CSS、字体、图片放到 CDN 上,提高资源加载速度。
- 缓存优化
项目中是否有做,首屏加载超过一个阈值,就告警之类的
我们对首页和核心业务页面做了 LCP 和白屏时间的性能监控。我们设置了性能阈值(例如 LCP 超过 3s),一旦异常占比超过 10%,就会通过 Webhook 触发飞书/钉钉告警。同时我们也会采集用户网络环境、设备类型等辅助信息,定位慢加载是否和 CDN、网络波动或某版本资源相关。整个方案通过 Performance API + sentry
首屏相关
首屏加载指标细化:
- FP(First Paint)首次绘制
- FCP(First Contentful Paint)首次内容绘制,FP 到 FCP 中间其实主要是 SPA 应用 js 执行时间,太慢的话就会白屏太长
- FMP(First Meaningful Paint)主要内容呈现的时间
- LCP(Largest Contentful Paint)最大内容渲染,提现加载最大内容的呈现时间
- TTI 可交互时间 ssr 的时候要重点考虑
SSR 是终极方案
白屏时间 vs 首屏时间
- 白屏时间 FCP
- 首屏时间 LCP
计算:PerformanceObserver
Lighthouse
lighthouse 有哪些指标?
2022 年谷歌推出 web 核心指标计划,没有必要搞很多指标来衡量性能,核心 web 指标计划旨在简化场景,统一网页性能衡量指标; core web vitals:
- LCP(largest contentful paint)2.5s 内,专注于加载性能 为什么不是 FCP(First contentful Paint):大部分页面都有 loading 态,loading 开始的时候 fcp 计算已结束,意义不大
- INP(Interaction to Next Paint)网页对用户输入的响应速度 200ms 内
- CLS(Cumulative Layout Shift)小于 0.1,专注于视觉稳定性
加载优化
目标:加载少,加载快
- 加载的资源无非就以下几大类(越小越好)
- 图片
- css 实现
- 压缩
- 使用 webp/avif 边缘计算
- 懒加载 loading:lazy
- 视频管理 gif,google 做过一个实验,4M 的 gif,mp4 只要 500K,webm 只要 300K
- 响应式
- 字体
- 使用 woff2 比 woff 小 30%
- 指定 unicode-range
- js
- 按需引入 UI 库
- tree shaking,比如使用 lodash-es 代替 lodash
- 路由懒加载
- 压缩代码
- 基于 canvas 加载?
- CSS
- purgecss 移除没用到的样式
- 压缩代码
- 懒加载非关键的 css 借助 criticalcss
- 图片
- 加载资源越快越好
- 最大限度的利用缓存
- 配置 cache-control,ETag
- 做好分包策略
- hash/chunkhash/contenthash
- pwa
- 优化加载速度
- 14kb 原则
- 使用 CDN
- 开启 http2/http3
- dns-prefetch/preload/prefetch/preconnect
- 最大限度的利用缓存
SEO 相关
技术上,我认为 SEO 优化可以分为结构优化、性能优化和可爬取性优化三大块:
结构优化:我会确保页面使用语义化标签,比如
, , ,并合理设置 、<meta> 描述、关键词,以及 H1-H6 层级,利于搜索引擎理解内容结构; 性能优化:加快首屏加载时间,提升 Core Web Vitals 指标(像 LCP、CLS),对 SEO 也有直接影响;
可爬取性优化:我参与过使用 Next.js 实现 SSR(服务端渲染),解决传统 SPA 页面内容被搜索引擎抓不到的问题。同时也配置了 sitemap.xml、robots.txt 让搜索引擎更好地发现与索引页面;
- sitemap 诉搜索引擎网站有哪些页面、更新频率、优先级等,帮助其更快抓取收录,一般通过插件自动生成
- robots.txt 告诉搜索引擎哪些页面允许抓取、哪些禁止抓取,防止泄露隐私页面或浪费爬虫预算,用来控制爬虫权限,比如限制访问后台或接口路径,同时声明 sitemap 地址,方便收录。
最后结合 fb 有个 seo 工具,进一步自查;
内部脚手架是怎么设计的?怎么提升团队效率?
我主导开发了一个前端脚手架工具,核心基于 Node.js + Inquirer + commander,支持快速生成我们公司几种业务版图,tg 小程序项目,普通的 nextjs 项目,官网项目等等
目的是去创建一个项目,其次去预置一些通用代码,比如内部的一些代码,比如一些埋点,http 请求封装,以及一些常用的工具函数,其次在构建和发布方面,还有 docker 的生成与上传,ci 的一些配置等等,保持风格和样式的统一;
代码风格是如何统一的:eslint、prettier、style-lint;
eslint:侧重语法的检验,prettier:侧重格式的统一
推动落地了 Puppeteer 的测试框架,是怎么做的?
我们当时需要一个能模拟用户真实操作的端到端测试方案,选型时调研了 Puppeteer、Cypress 和 Playwright:
最终选 Puppeteer,Puppeteer 配置更轻量,更符合当时的场景,
编写了基于页面路由的自动化登录 + 功能回归脚本脚本,后续就交给小组的其他同事负责
推动这个方案前后花了两周时间调研 + POC,落地后有效降低线上回归 Bug 20% 以上。
镜像体积太大?
- 尽量减少层级、构建基础镜像;
- 考虑从更换基础镜像源的方式
- 看看是否使用了过于臃肿的镜像源 因为 Alpine 镜像和类似的其他镜像都经过了优化,其中仅包含最少的必须的软件包;alpine 是轻型 Linux 发行版,提供了包管理工具 比如 nginx:最新版本 142mb,alpine 的只有 23.4MB node:14 846MB,alpine:172MB 编译好的文件复制进来即可
项目亮点
反作弊
- 接口层面
- 限制单用户请求频率
- 指纹
- 接口加密
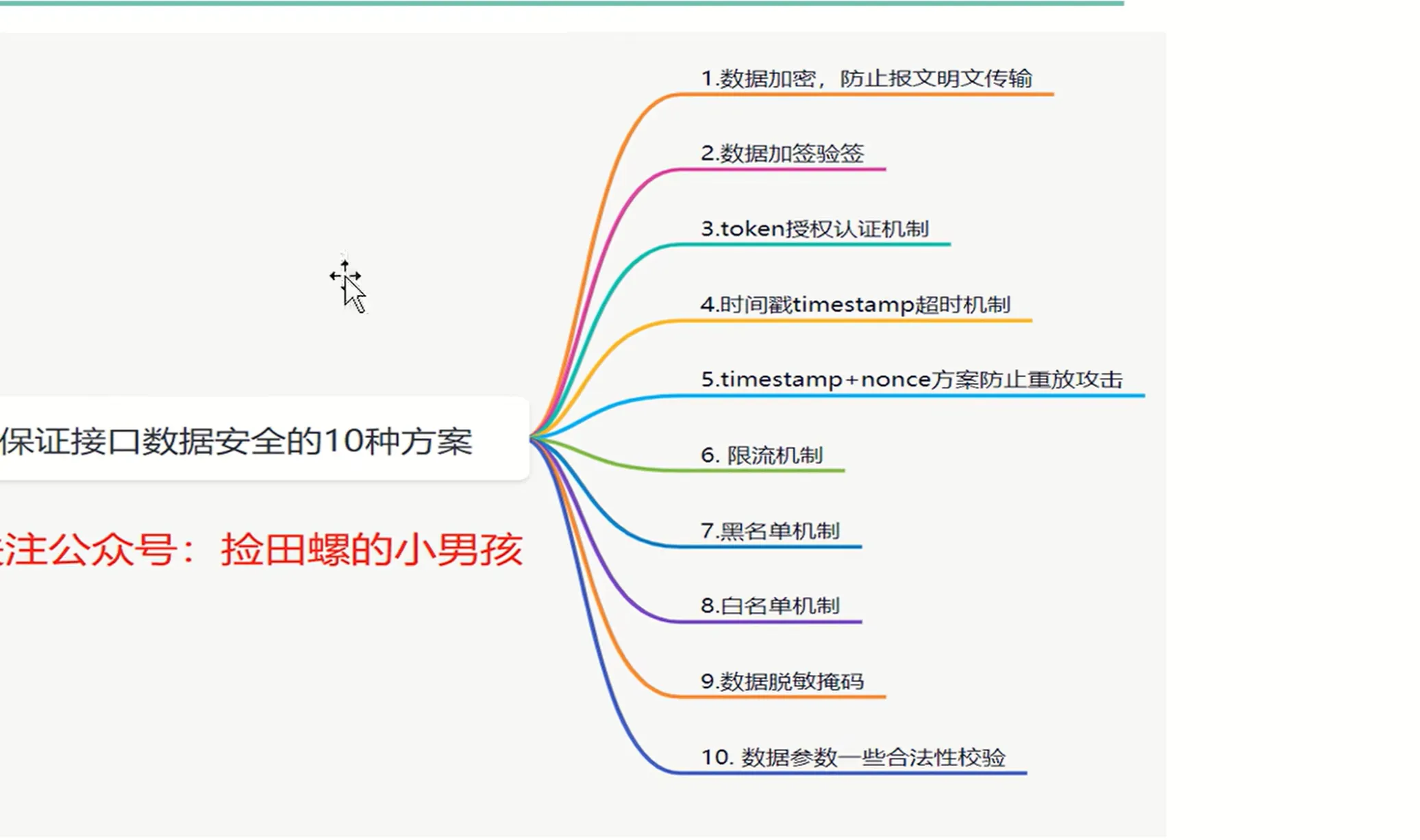
接口加密
大文件上传和断点续传和显示进度条
核心:分片 + 并发 + 合并
将文件用 File.slice 方法分片(比如每片 1MB),生成每一片的唯一 hash 标识。然后用多线程并发上传每个 chunk。上传前我会向后端请求已上传的 chunk 列表,实现断点续传。上传过程中,我会监听 axios.onUploadProgress 实时更新进度条。最后所有分片上传完成后,请求后端合并文件。
鉴权
Wheel 自己实现
graphQL
水印
通过 document.createElement(‘canvas’);去绘制水印,相当于加一个蒙层去绘制水印,但这样有个缺陷就是我们做前端的会打开控制台,可以把水印给去掉,为了防止这个,采用 mutation observe 去监听 dom 是否有变化,如果有变化重新给他加上
微前端
webpack 联邦模块
小程序 Taro,是如何实现多端编译的
Taro 是京东·凹凸实验室开源的跨端框架,使用 React 语法编写,可以编译成微信小程序、H5、RN 等,一套代码,编译多端
Taro 会将使用 JSX 编写的组件代码经过 AST 分析 → 转换为对应平台的模板语言(如 wxml、html)。
hybrid app
PWA 离线缓存是怎么做的
PWA 的离线能力是通过注册 Service Worker,在安装阶段预缓存资源,在 fetch 阶段拦截请求优先从缓存返回,从而实现离线访问。
错误监控,搭建过程
一次导出 10 万条数据为 excel,页面卡顿,如何处理
- 后端导出
- web worker
- 分批
SSR CSR SSG ISR
SSR:
- 首屏加载快,SEO 友好
- 内容对搜索引擎和爬虫友好
- 对低性能设备更友好
但是:
- 服务端压力大,可能响应慢
- 首次渲染需要等待服务端完成
- 服务器复杂度较高
适用于:新闻站、博客、电商首页、SEO 要求高的页面
CSR:
- 交互丰富,体验流畅
- 减轻服务器压力
- 前后端分离灵活
但是
- 首屏加载慢,白屏时间长
- SEO 较差
- 依赖 JS,关闭 JS 时页面无内容
适用于:SPA 应用、后台管理系统、用户操作频繁页面
SSG:
- 访问速度极快
- 无需服务器渲染压力
- SEO 友好
- 部署简单
但是
- 生成时长长,构建时间随内容量增加
- 内容不实时,更新需要重新构建
适用于:文档网站、博客、产品官网、内容变化不频繁站点
ISR:
- 结合了 SSG 的速度和 SSR 的实时性
- 页面按需静态生成和更新
- 服务器负载均衡
但是
- 实现复杂,需要缓存和增量更新机制
- 可能存在短暂的内容过期窗口
适用于:大型内容站点、电商平台(首页+部分商品页)
白屏的可能出现的时间点
页面白屏的可能原因包括:
- 网络请求失败(DNS、服务器),
- 关键资源(HTML、CSS、JS)加载失败,
- JS 执行报错阻塞渲染,异步数据未加载导致无内容渲染,
- 路由配置错误导致组件未渲染。
排查时可以从 Network、Console、Elements 面板逐步定位,关键是保证关键资源加载无误和 JS 逻辑正确执行。
h5 竖屏切换到横屏要做什么处理
H5 页面从竖屏转为横屏时,主要需要监听 resize 或 orientationchange 事件,实时获取屏幕尺寸和方向,动态调整页面布局和样式。通常结合 rem 适配和媒体查询处理不同方向的样式差异。针对横屏可能出现的视口单位异常、布局错乱等问题,需要做兼容处理。对于某些业务场景,还会给用户做方向切换提示,确保体验一致。
js 的堆栈和 v8 的堆栈
在 JavaScript 语言层面,堆和栈是内存管理的抽象概念,基本类型存储在栈中,引用类型存储在堆中。栈用于管理函数调用的执行上下文,访问快且自动管理;堆用于存储对象,大小动态且需要垃圾回收。而 V8 引擎是 JS 的具体实现,它维护了调用栈来跟踪函数调用,并实现了堆内存的分配和高效垃圾回收机制。V8 还做了优化如分代回收、新生代老生代区分等,提高性能。简单来说,JS 堆栈是语言模型,V8 堆栈是具体引擎实现,两者层级不同。
一个 url 打开很慢,要怎么定位问题
“慢”可以是后端问题、前端资源问题、网络问题或渲染问题,我会按以下步骤分析”
步骤 1:先确认是“所有人都慢”还是“部分人慢”
- 所有人慢:服务器、后端、部署问题
- 地域慢、偶现:网络、CDN、DNS 问题
- 工具:
- 日志系统(采样用户耗时)
- CDN 日志、测速平台、监控系统(如阿里云 ARMS)
步骤 2:看 DNS、TCP、TTFB 耗时,在 Network 面板中分析
- DNS Lookup:慢 → 换 DNS、使用缓存
- SSL Handshake:慢 → HTTPS 证书部署问题
- TTFB(首字节时间):慢 → 后端接口慢、数据库慢
步骤 3:资源加载问题
- JS/CSS 文件过大未分包(看 Network)
- 图片体积过大(未压缩、未懒加载)
- 请求数量多(未合并、重复请求) 解决方案:
- Webpack 分包(Code Splitting)
- 图片压缩 + 懒加载
- HTTP/2 并发
步骤 4:主线程阻塞或 JS 太大:Performance 面板查看:
- 紫色大块 JS → JS 包太大
- Layout/Reflow 频繁 → 页面结构复杂 解决方案:
- 异步加载 JS(defer、lazy)
- 动画节流、DOM 简化、CSS 复杂度降低
步骤 5:首屏优化问题
- 是否开启 SSR(服务端渲染)
- 是否启用骨架屏 / loading 占位
- 是否懒加载首屏外资源
我会先用浏览器 DevTools 的 Network 面板排查是否是 DNS、SSL、接口响应慢的问题。再通过 Performance 分析主线程是否阻塞,比如 JavaScript 执行是否太重。之后我会看资源加载是否太多或太大,是否有图片未压缩或请求未懒加载。最后看是否首屏渲染策略不当,比如没有 SSR、异步数据加载阻塞渲染等。必要时结合后端日志和接口响应时间进一步定位瓶颈。